Intro
This book is on driver development using Rust. You get to procedurally write a UART driver for a RISCV chip called ESP32C3 and a Qemu-riscv-virt board.
If you have no idea what a UART driver is, then you have nothing to worry about. You'll get a hang of it along the way.
This is NOT a book on embedded-development but it will touch up on some embedded-development concepts here and there.
To learn about Rust on embedded, you are better off reading The Embedded Rust Book.
Book phases, topics and general flow.
The book will take you through 5 phases :
Phase 1:
Under phase 1, you get to build a UART driver for a qemu-riscv virtual board. This will be our first phase because it will take you through the fundamentals without having to deal with the intricacies of handling a physical board. You won't have to write flashing algorithms that suite specific hardware. You won't have to read hardware schematics.
The code here will be suited for a general virtual environment.
The resultant UART driver at the end of this phase will NOT be multi_thread-safe.
Phase 2:
We will try to improve our UART driver code to conform to standard APIs like PAC and HAL. This phase will try to show devs how to make standard drivers that are more portable.
If you have no idea what HAL and PACs are, you hav nothing to worry about. You'll learn about them along the way.
Phase 3:
Both Phase 1 and 2 focus on building a UART driver for a virtual riscv board, BUT phase 3 changes things up and focusses on porting that UART code to a physical board.
We will modify the previously built UART driver so that it can run on an esp32 physical board. We'll set up code harnesses that assist in flashing, debugging, logging and testing the driver-code on the physical board.
On normal circumstances, people use common pre-made and board-specific tools to do the above processes : ie testing, logging, debugging and flashing.
For example, developers working with Espressif Boards usually use Espressif tools like esptool.py.
We will not use the standard esp-tools but we will use probe-rs, this is because esp-tools abstract away a lot of details that are important for driver-devs to master. Esp-rs tools are just too good to use in our use-case... it would be awesome if we write our own flashing algorithms and build or own logging module. Probe-rs is hack-able and allows one to do such bare activities.
We will however imitate the esp-tools.
The driver produced in this phase will still NOT be multi_thread-safe.
Phase 4:
Under Phase 4, we start making our driver to be multi-thread safe. This will be first done in a qemu virtual environment to reduce the complexity. After we have figured our way out of the virtual threads, we will move on to implementing things on the physical board.
Phase 5:
In phase 5, We'll do some brush-up on driver-security and performance testing.
Why the UART?
The UART driver was chosen because it is simple and hard at the same time. Both a beginner and an experienced folk can learn a lot while writing it.
For example, the beginner can write a minimal UART and concentrate on understanding the basics of driver development; No-std development,linking, flashing, logging, abstracting things in a standard way, interrupt and error-handling...
The pseudo_expert on the other hand can write a fully functional concurrent driver while focusing on things like performance optimization,concurrency and parallelism.
A dev can iteratively work on this one project for a long time while improving on it and still manage to find it challenging on each iteration. You keep on improving.
Moreover, the UART is needed in almost all embedded devices that require some form of I/O; making it a necessary topic for driver developers.
The main aim here is to teach, not to create the supreme UART driver ever seen in the multiverse.
What this book is NOT
This book does not explain driver development for a particular Operating System or Kernel. Be it Tock, RTOS, Windows or linux. This book assumes that you are building a generic driver for a bare-metal execution environment.
Quick links
To access the tutorial book, visit : this link
To access the source-code, visit this repo's sub-folder
This is an open-source book, if you feel like you want to adjust it...feel free to fork it and create a pull-request.
Prerequisites for the Book
The prerequisites are not strict, you can always learn as you go:
-
Computer architecture knowledge : you should have basic knowledge on things like RAM, ROM, CPU cycle, buses... whatever you think architecture is.
-
Rust knowledge : If you've read the Rust book, you should be fine. This doesn't mean that you should have mastered topics like interior mutability, concurrency or macros...these are things that you can learn as you go. Ofcourse, you will need them, but it's better to learn them on the job for the thrill of it.
-
Have an esp32-c3... or any riscv board that you are comfortable with.
-
Have some interest in driver development. Learning without interest is a mental torture. Love yourself.
And finally, have lots of time and patience.
Goodluck.
Intro to Drivers
This chapter is filled with definitions.
And as you all know, there are NO right definitions in the software world. Naming things is hard. Defining things is even harder.
People still debate what 'kernel' means. People are okay using the word 'serverless' apps. What does AI even mean? What is a port? What is a computer even? It's chaos everywhere.
So the definitions used in this book are constrained in the context of this book.
What's a driver? What's firmware?
Drivers and firmwares do so many things. It is an injustice to define them like how I have defined them below.
In truth, the line between drivers and firmware is very thin. (we'll get back to this... just forget that I mentioned it).
But here goes the watered down definitions...
Firmware
Firmware is software that majorly controls the hardware. It typically gets stored in the ROM of the hardware.
For example, an external hard-disk device has firmware that controls how the disks spin and how the actuator arms of the hard-disk do their thing.
That firmware code is independent of any OS or Runtime... it is code specifically built for that hard-disk's internal components. The 0s and 1s of the firmware are stored in a place where the circuitry of the hard-disk can access and process.
You may find that the motherboard of the hard-disk has a small processor that fetches the firmware code from the embedded ROM amd processes it. See the figure below.

Driver
On the other hand, a Driver is software that also controls the hardware AND provides a higher level interface for something like a kernel or a runtime. The driver is typically stored as part of the kernel.
The above definitions are confusing? Ha?
Here is an image to confuse you further...
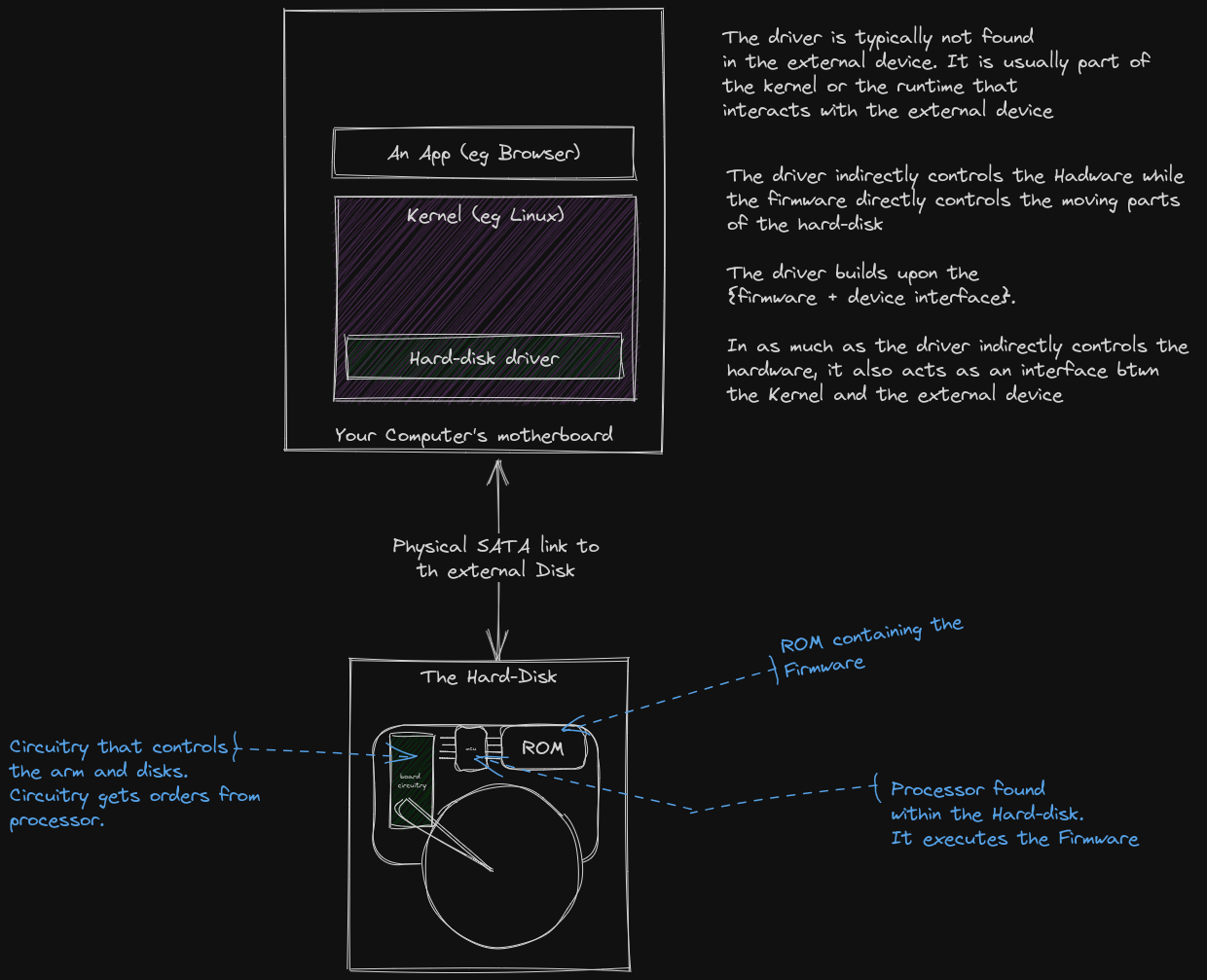
A driver typically sits in-between a high-level program and the physical device.
The high level program could be a kernel in this case. And the physical device could be an hard-disk attached to the motherboard.
The driver has 2 primary functions :
- Control the underlying device. (the hard-disk)
- Provide an interface for the kernel/higher-level program to interact with. The interface could contain things like public functions, data_structures and message passing endpoints that somehow manipulate how the driver controls the underlying device...
Here is a Bird's eye-view of the driver-to-firmware ecosystem:

Let's break down the two main roles of the driver in the next chapter...
But before we turn the page, remember when we said that the line between drivers and firmware is thin?
Well... here is an explanation
Role 1 : Controlling the Physical device below
TLDR :
Software controls the hardware below by either Direct Register Programming or Memory Mapped Programming. This can be done using Assembly language, low-level languages like C/Rust, or a mixture of both.
In the previous page, we concluded that BOTH firmware and drivers control hardware.
So, what does controlling hardware mean? How tf is that possible?
What is Hardware??
Hardware in this case is a meaningful combination of many electronic circuits.
A Hard-disk example
For example, a Hard Disk is made up of circuits that store data in form of magnetic pockets, handle data-retrival, handle heat throttling, data encryption... all kinds of magic.
In fact, let's try to make an imaginary-over-simplified DIY hard-disk.
Here's a sketch...
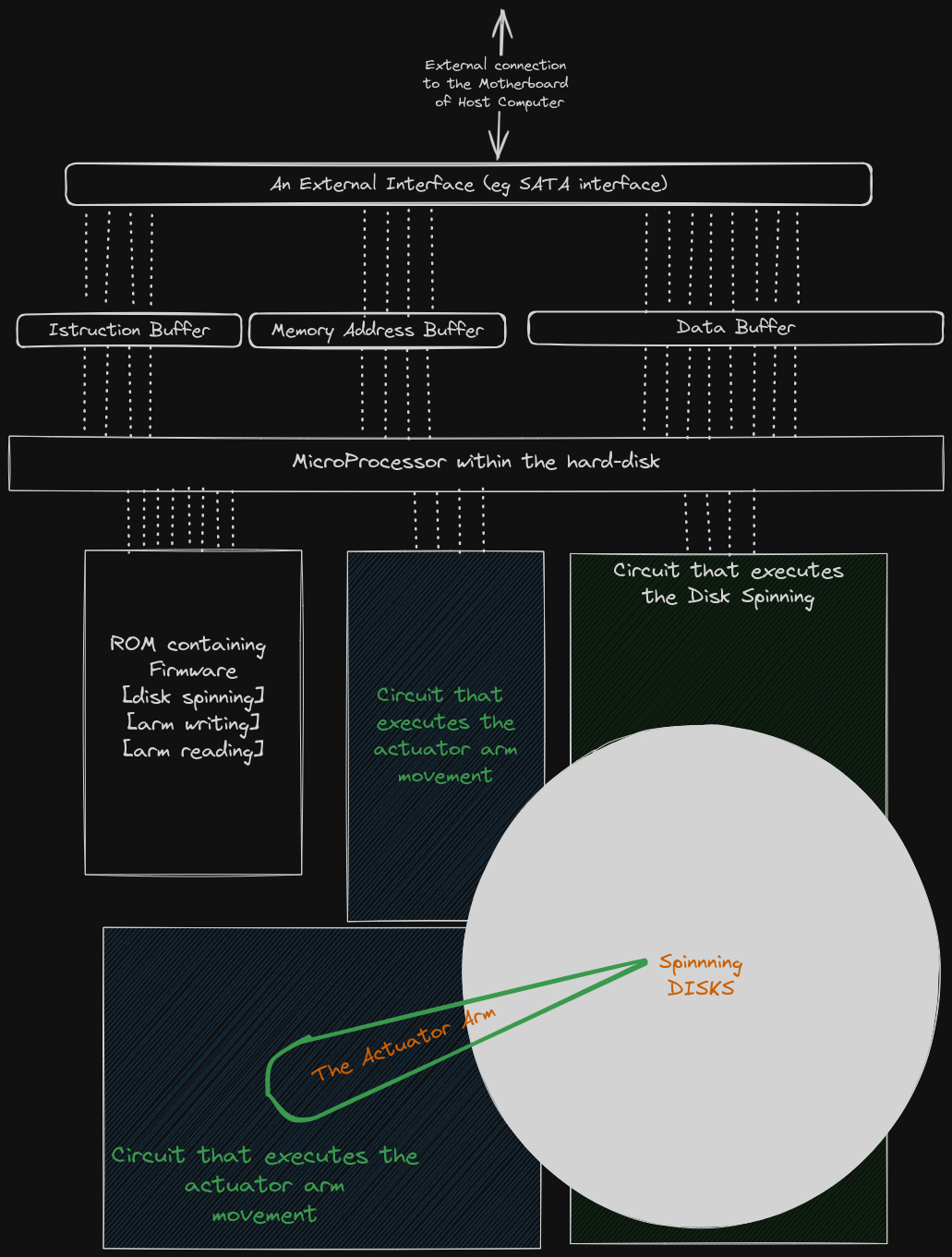
Here is a break-down of the above image.
-
The External interface
The external interface is the physical port that connects the Hard-disk to the host computer.
This interface has 2 functions:- The interface receives an instruction, a memory address and data from the host computer and respectively stores them in the
Instruction Buffer,Memory Address BufferandData Bufferfound within the hard-disk. The acceptable instructions are only two:READ_FROM_ADDRESS_XandWRITE_TO_ADDRESS_X.
TheMemory Address Buffercontains the address in memory where the host needs to either read from or write to.
TheData Buffercontains the data that has either been fetched from the disk or is waiting to written to the disk.
- The interface also receives data from within the hard-disk and transmits them to the Host computer
- The interface receives an instruction, a memory address and data from the host computer and respectively stores them in the
-
The ROM contains the Hard-disk's firmware. The Hard-disk's firmware contains code that ...
- handles heat throttling
- handles the READ and WRITE function of the Actuator Arm
- handles the movement of the Actuator Arm
- handles the spinning speed of the disks
-
A small IC or processor that fetches and executes both the Hard-disk's firmware and the instructions stored in the
Instruction Buffer.The micro-processor continuously does a fetch-execute cycle on both the
Instruction Bufferand the ROM.If the instruction fetched from the
Instruction BufferisREAD_FROM_ADDRESS_X, the processor begins the READ operation.
If the instruction fetched from theInstruction BufferisWRITE_TO_ADDRESS_X, the processor begins the WRITE operation.Steps of the READ operation...
- The processor fetches the target memory address from the
Memory Address Buffer. - The processor fetches & executes the firmware code to spin the disks accordingly in order to facilitate a read from the target address.
- The processor fetches & executes firmware code to move the Actuator Arm to facilitate an actual read from the span disks.
- After the read, the processor puts the fetched data in the
Data Buffer - The External Interface fetches data from the
Data Bufferand transmits it to the Host. - The processor clears the
Instruction Buffer,Memory Address BufferandData Bufferin order to prepare for a fresh read/write operation. - The Read operation ends there.
Steps of the WRITE operation...
- The processor fetches the target memory address from the
Memory Address Buffer. - The processor acquires the data that is meant to be written to the Hard-disk. This data is acquired from the
Data Buffer. - The processor fetches & executes firmware code to spin the disks accordingly in order to facilitate a write to the target address.
- The processor fetches & executes firmware code to move the Actuator Arm to facilitate a write.
- The processor clears the
Instruction Buffer,Memory Address BufferandData Bufferin order to prepare for a fresh read/write operation. - The Write operation ends there.
- The processor fetches the target memory address from the
A manual driver?
If we were in a zombie apocalypse and we had no access to a computer for us to plug in a hard-drive, how would we have stored data into the hard-disk?
We could store data directly without using a computer with an Operating system that has hard-disk drivers. All we have to do is to supply meaningful electric signals to the external interface of the Hard-disk. You could do this using wires that you collected from the car you just stripped for parts. We are in an apocalypse, remember?
For example, to store the decimal number 10 into the address 0b0101, we could do this...
Strip, the external interface off and access the 3 registers directly: The Data Buffer register, Instruction Buffer register & Memory Address Buffer register.
From there, we could supply the electrical signals as follows...
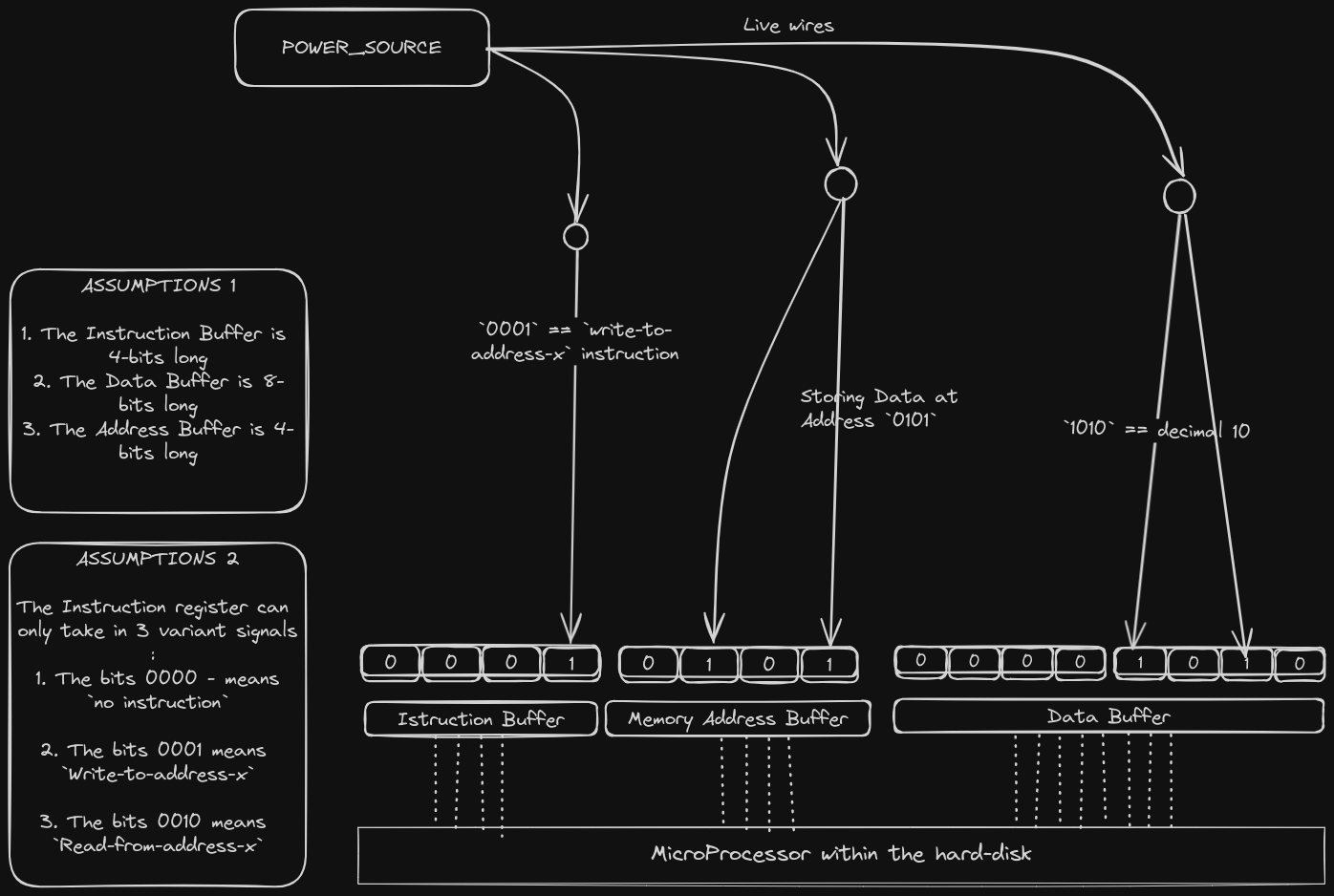
Of-course, this experiment is very hard to do in real life. But come on, we are in an apocalypse and we have just build ourselves an 8-bit DIY hard-disk. Kindly understand.
Programming
We are developers, we automate everything... especially when it is unnecessary.
So how do we automate this manual manipulation of Hard-disk registers? How??
Let us imagine that in the middle of the apocalypse, we found a host computer where we can plug in our DIY hard-disk.
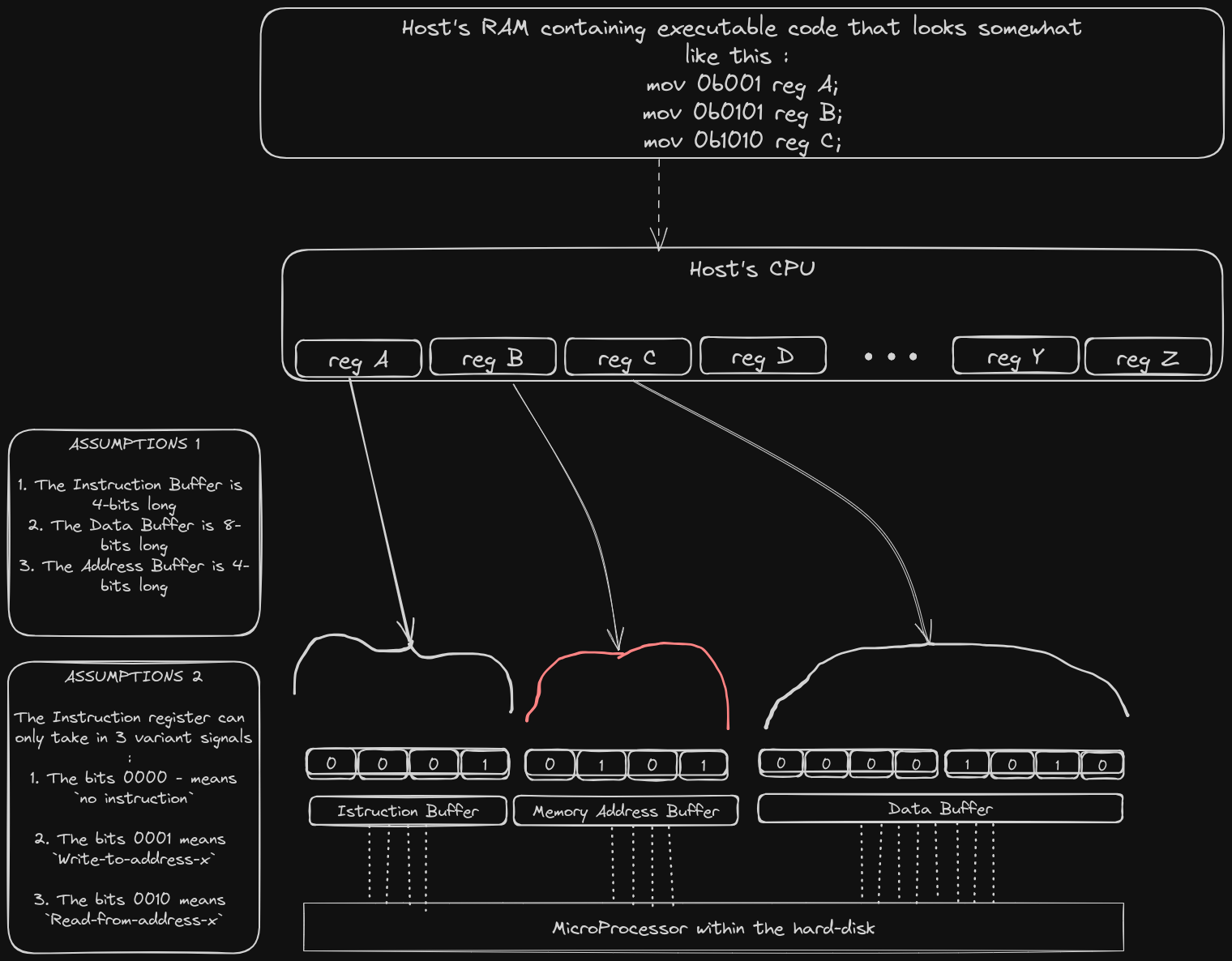
Solution 1: Direct Register Programming
Now that we have access to a Host computer with a CPU, we can attach all the 3 registers DIRECTLY to the CPU of the host computer as shown in the figure below.
To control which signals reach the individual bits of the 3 registers, we can write some assembly code to change the values of the native CPU registers. It is our assumption that the electrical signals will find their way to the attached registers... (basic electricity)
This solution gets the job done.
This solution is typically known as Direct register programming. You directly manipulate the values of the CPU registers, which in turn directly transfer the values to the registers of the external device.
Solution 2: Memory Mapped Programming
The CPU has a limited number of registers. For example, the bare minimum RiscV Cpu has only 32 general registers. Any substantial software needs more than 32 registers to store variables. The RAM exists because of this exact reason, it acts as extra storage. In fact the stack of most softwares gets stored in the RAM.
The thing is... registers are not enough.
So instead of directly connecting the Hard-disk registers to the limited CPU registers, we could add the external-device registers to be part of the address space that the CPU can access.
We could then write some assembly code using standard memory access instructions to indirectly manipulate the values of the associated hard-disk registers. This is called Memory-mapped I/O programming (mmio programming).
MMIO maps the registers of peripheral devices (e.g., I/O controllers, network interfaces) into the CPU’s address space. This allows the CPU to communicate with these devices using standard memory access instructions (load/store)
This is the method that we will stick to because it is more practical.
You could however use Direct Register Programming when building things like pace-makers, nanobots or some divine machine that is highly specialized and requires very little indirection when fetching or writing data to addresses.
This is because dedicated registers typically perform better than RAMS and ROMS in terms of access-time.
Summary
The driver controls the hardware below by either Direct Register Programming or Memory Mapped Programming. This can be done in Assembly, low-level languages like C/Rust, or a mixture of both.
Role 2: Providing an Interface
The driver acts as an interface between the physical device and the kernel.
In this case, the 'physical device' is inclusive of its internal firmware.
The Driver abstracts the device as a simplified API.
We will learn about HALs and PACs in future chapters. You can ignore them for now.
{this is an undone chapter. Abstraction is an art. The author is still trying to find his rhythm.}
{For devs with stable styles, you can edit this page.}
Types of Drivers
Classifications and fancy words do not matter, we go straight to the list of driver-types.
Drivers are classified according to :
- How close the driver is to the metal.
- What the function of the driver is.
Drivers classified by their level of abstraction.
Like earlier mentioned, drivers are abstractions on top of devices. And it is well known that abstractions exist in levels; you build higher-level abstractions on top of lower level abstractions.
Here are the two general levels in the driver-world.
-
Function drivers : these drivers implement functions that directly manipulate the external device's registers. You could say that these drivers are the OG drivers. They are at the lowest-level of abstraction. They are one with the device, they are one with the metal.
-
Filter drivers/ Processing drivers/ Wrapper drivers: These drivers take input from the function drivers and process them into palatable input and functions for the kernel. They can be seen as 'adapters' between the function-driver and the kernel. They can be used to implement additional security features. Point being, their main function is wrapping the function-driver.
Oh look... this 👇🏻 is what we were talking about... thanks windows for your docs.
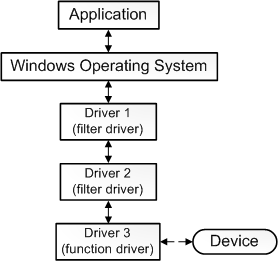
This image was borrowed from the Windows Driver development docs
A driver stack is a collection of different drivers that work together to achieve a common goal.
Drivers classified by function
This classification is as straightfoward as it seems. eg Drivers that deal with hard-disks and SSDs are classified as storage drivers. More examples are provided below:
- storage drivers : eg ssd drivers
- Input Device Drivers
- Network Drivers
- Virtual drivers (Emulators)
- This list can be as long as one can imagine... but I hope you get the drift
IMO, classification is subjective, a driver can span across multiple classifications.
Bare Metal Programming
Bare Metal Programming !!!!!!!!!!🥳🥳🥳🥳
Welcome to the first cool chapter.
Bare metal programming is the act of writing code that can run on silicon without any fancy dependencies such as a kernel.
This chapter is important because both Firmware and Drivers are typically Bare-metal programs themselves.
This chapter takes you through the process of writing a program that does not depend on the standard library; A program that can be loaded and ran on any board with a processor and some bit of memory... be it an arduino, an esp, a pregnancy-test-device or a custom board that you manufactured in your bedroom.
Here are 2 alternative resources :
Philipp Oppermann's blog covered Bare-metal programming very well. Philipp's blog covers the topic across two chapters, you can read them here 👇🏽:
- Chapter 1 : A Freestanding Rust Binary
- Chapter 2 : A Minimal Rust Kernel
The Embedonomicon gives you a more detailed and systematic experience.
Two cents : Start with the Blog and then move on to the Embedonomicon.
Machine code
From your Computer architecture class, you learnt that the processor is a bunch of gates cramped up together in a meaningful way. A circuit of some sort.
You also learnt that each processor implements an ISA (Instruction Set Architecture).
As long as you can compile high level code into machine code that is within the bounds of the ISA, that CPU will gladly execute your code. You don't even have to follow a certain ABI in order for that code to run.
The main point here is that : "Machine code that follows a certain ISA can run on any processor that implements that ISA." This is because the processor is a DIRECT implementation of the ISA specifications.
So a home-made processor that you built in your room can run Rust code as long as that rust code gets compiled into machine code that follows the ISA specifications of your custom processor.
Dependencies
A dependency refers to a specific software component or library that a project relies on to function properly.
For example, the hello-world program below uses the time library as a dependency:
use time; fn main(){ println!("Hello world!!!"); let wait_time : Duration = time::Duration::from_seconds(5); thread::sleep(wait_time); }
Default dependencies
By default, all rust programs use the std library as a dependency. Even if you write a simple hello-world or an add-library, the contents of the std::prelude library get included as part of your code as if you had written it as follows...
use std::{self, prelude::*}; // this line is usually not there... but theoretically, // your compiler treats your code as if this line was explicitly declared here fn main(){ println!("Hello world!!!"); }
So ... what is the standard library? What is a prelude?
The Standard Library
The standard library is a library like any other... it is just that it contains definitions of things that help in very essential tasks. Tasks that are expected to be found in almost every OS.
For example, it may contain declarations & definitions of file-handling functions, thread-handling functions, String struct definition, ... etc
You can find the documentation of the rust standard library here.
Below is a story that explains more about standard libraries (disclaimer: the story does not even explain the actual modules of the standard library).
Story time
You can skip this page if you already understand ...
- What the standard library is
- Why it exists
- The different standards that may be followed
System Interface Standards
Long ago ... once upon a time (in the 70s-80s), there were a lot of upcoming operating systems. Each operating system had its's own features. For example, some had graphical interfaces, some didn't. Some could run apps using multi-threading capabilities, others didn't. Some had file systems that contained like 100 functions... others had like 10 file-handling functions.
It was chaos everywhere. For example : the open_file() function might have had different names across many operting systems. So if you wrote an app for 3 OSes, you would have re-written your code 3 times just because the open_file function was not universal.
It was a bad time to be an application developer. You either had to specialize in writing apps for one operating system OR sacrifice your sanity and learn the system functions of multiple Operating systems.
To make matters worse... the individual operating systems were improving FAST, it was a period when there were operating system wars... each new weekend introduced breaking changes in the OS API...so function names were changing, file_handling routines were changing, graphical output commands were changing. CHAOS! EVERYWHERE.
So developers decided that they needed some form of decorum for the sake of their sanity.
They decided to create common rules and definitions on the three topics below :
- Basic definitions of words used in both kernel and application development
- System interface definition
- Shell and utilities.
So what the hell are these three things?
1. Basic definitions
Just as the title says, before the devs made rules, they had to first know that they were speaking the same language. I mean... how can you make rules about something that you don't even have a description for?
They had to define the meaning of words. Eg "What is a process? What is an integer? What is a file? What is a kernel even?
Defining things explicitly reduced confusion.
They had to ...
- Agree on the definition of things ie terminology.
- Agree on the exact representation of data-types and their behavior. This representation does not have to be the same as the ABI that you are using, you just have to make sure that your kernel interface treats data-types as defined here.
- Agree on the common constants : For example error_codes and port numbers of interest ...
2. System Interface
As earlier mentioned, each kernel had different features and capabilities... some had dozens of advanced and uniquely named file-handling functions while others had like 2 poorly named and unique file-handling functions.
This was a problem. It forced devs to have to re-write apps for each OS.
So the devs sat down and created a list of well-named function signatures... and declared that kernel developers should implement kernels that us those exact signatures. They also explicitly defined the purpose of each of those functions. eg
void _exit(int status); # A function that terminates a process
You can find the full description of the _exit function under POSIX.1-2017 and see how explicit the definitions were.
This ensured that all kernels, no matter how different, had a similar interface. Now devs did not need to re-write apps for each OS. They no longer had to learn the interfaces of each OS. They just had to learn ONE interface only.
These set of functions became known as the System interface.
You can view the POSIX system interface here
3. Shell and its utilities
The Operating system is more than just a kernel. You need the command line. You may even need a Graphic User Interface like a Desktop.
In the 1980's, shells were the hit. So there were dozens of unique shells, each with their own commands and syntax.
The devs sat down and declared the common commands that had to be implemented or availed by all shells eg ls, mv, grep, cd...
As for the shell syntax... well... I don't know... the devs tried to write a formal syntax. It somehow worked, but people still introduced their own variations. Humanity does not really have a universal shell syntax.
(which is good, bash syntax is horrifying... the author took years to get good at Rust/JS/C/C++, but they're sure they'll take their whole life to get comfortable with bash. Nushell to the rescue.)
There are a few standards that cover the above 3 specifications. Some of them are:
- POSIX standard
- WASI (WebAssembly System Interface)
- Windows API (WinAPI)
Entry of the standard library
Why is this 'System Interface Standards' story relevant?
Well... because the functions found in the Rust standard library usually call Operating system functions in the background(i.e POSIX-like functions). In other words, the source-code for the standard library may call POSIX-system functions in the background.
POSIX compliance
If you look at the list of system functions specified by posix, you might get a heart-attack. That list is so Long!!.
What if I just wanted to create a small-specialized kernel that does not have a file-system or thread-management? Do I still have to define file-handling functions? Do I still have to define thread-management functions? - NO!, that would be a waste of everyone's time and RAM.
So we end up having kernels that define only a subset of the posix system interfaces. So Kernel A may be more Posix-compliant than Kernel B just because kernel A implements more system interfaces than B... it is up to the developers to know which level of tolerance they are fine with.
The level of tolerance is sometimes called Posix Compliance level. I find that name limiting, I prefer 'level of tolerance'.
C example
Read about The C standard library and its relation to System interfaces from this wikipedia page.
Bare-metal
So by now you understand what the standard library is.
You understand why it exists.
You somehow understand its modules and functions.
You understand that the standard library references and calls system functions in its source code. The Std assumes that the underlying operating system will provide the implementations of those system functions.
These system function definitions can be found in files found somewhere in the OS.
You understand that the interface definition of a standard library is 'constant'. ( i.e it is standardized, versionized and consistent across different platforms)
You understand that the implementation of a standard library is NOT constant because It is OS-dependent. For example the interfaces of the libc library is constant across all OSes but libc's implementations is different across all OSes; In fact the libc implementations have different names ... we have glibc for GNU-Linux's libc and CRT for windows' libc. GNU-linux even has extra implementations such as musl-libc. Windows has another alternative implementation called MinGW-w64
No-std
Most rust programs depend on the standard library by default, including that simple 'hello world' you once wrote. The standard library on the other hand is dependent on the underlying operaring system or execution environment.
For example, the body of std::println! contains lines that call OS-defined functions that deal with Input and output eg write() and read().
Drivers provide an interface for the OS to use, meaning that the OS depends on drivers... as a result, you have to write the driver code without the help of the OS-dependent Standard Library. This paragraph sounds like a riddle ha ha... but you get the point... to write a driver, you have to forget about help from the typical std library. That std library depends on your driver code... the std library depends on you.
When software does not depend on the standard library, it is said to be a bare-metal program. It can just be loaded to the memory of a chip and the physical processor will execute it as it is.
Bare metal programming is the art of writing code that assumes zero or almost-no hosted-environment. A hosted environment typically provides a language runtime + a system interface like POSIX.
We will procedurally create a bare metal program in the next few sub-chapters.
Execution Environments
An Execution environment is the context where a program runs. It encompasses all the resources needed to make a program run.
For example, if you build a video-game-plugin, then that plugin's execution environment is that video-game.
In general software development, the word execution-environment usually refers to the combination of the processor-architecture, the kernel, available system libraries, environment variables, and other dependencies needed to make apps run.
Here is more jargon that you can keep at the back of your head:
The processor itself is an execution environment.
If you write a bare-metal program that is not dependent on any OS or runtime, you could say that the processor is the only execution environment that you are targeting.
The kernel is also an execution environment. So if you write a program that depends on the availability of a kernel, you could say that your program has two exeution environments; The Kernel and the Processor.
The Browser is also an execution environment. If you write a JS program, then your program has 3 execution environments: The Browser, the kernel and the Processor.
I hope you get the drift, the systems underneath any sotware you write is part of the execution environment.
Chips and boards are mostly made from silicon and fibreglass. Metal forms a small percentage(dopants, connections).
I guess we should saybare-silicon programminginstead ofbare-metal programming?
Disabling the Standard Library
A earlier mentioned, when you write drivers, you cannot use the standard library. But you can use the core-library.
So what is this core library? (also known as lib-core).
Even before we discuss what the core library entails, lets answer this first:
How is it possible that the core library can get used as a dependency by bare-metal apps while the std library cannot get used as a dependency? How are we able to use the core library on bare metal?
well...Lib-core functions can be directly compiled to pure assembly and machine code without having to depend on pre-compiled OS-system binary files. Lib-core is dependency-free.
Lib-core is lean. It is a subset of the std library. This means that you lose a lot of functionalities if you decide to use lib-core ONLY.
Losing the std library's support means you forget about OS-supported functions like thread management, handling the file system, heap memory allocation, the network, random numbers, standard output, or any other features requiring OS abstractions or specific hardware. If you need them, you have to implement them yourself. The table below summarizes what you lose...
| feature | no_std | std |
|---|---|---|
| heap (dynamic memory) | * | ✓ |
| collections (Vec, BTreeMap, etc) | ** | ✓ |
| stack overflow protection | ✘ | ✓ |
| init code before main | ✘ | ✓ |
| libstd available | ✘ | ✓ |
| libcore available | ✓ | ✓ |
* Only if you use the alloc crate and use a suitable allocator like alloc-cortex-m.
** Only if you use the collections crate and configure a global default allocator.
** HashMap and HashSet are not available due to a lack of a secure random number generator.
You can find lib-core's documentation here
You can find the standard library's documentation here
The Core library
The Rust Core Library is the dependency-free foundation of The Rust Standard Library.
That is such a fancy statement... let us break it down.
Core is a library like any other. Meaning that your code can depend on it. You can find its documnetation at this page
What does the Core library contain? What does it do?
- Core contains the definitions and implementations of primitive types like
i32,char,booletc. So you need the core library if you are going to use primitives in your code. - Core contains the declaration and definitions of basic macros like
assertandassert_eq. - Core contains modules that provide basic functionalities. For example, the
arraymodule provides you with methods that will help you in manipulating an array primitive.
What does the core library lack that std has?
Core lacks libraries that depend on OS-system files and OS-level services.
For example, core lacks the following modules that are found in the std library ... mostly because the modules deal with OS-level functionalities.
std::threadmodule. Threading is a service that is typically provided by a kernel.std::envmodule. This module provides you with ways to Inspect and manipulate a process’ environment. Processes are usually an abstration provided by an OS.std::backtracestd::boxedstd::osstd::string
Look for the rest of the missing modules and try to answer the following questions :
- "why isn't this module not found in core?",
- "if it were to be implemented in core, how would the module interface look like?".
The above 2 questions are hard.
In the past, the experimental core::io did not exist, but now it does because the above two questions were answered(partially). It is still an ongoing answer.
Something to note, just because a module's name is found in both std and core, it is not a guarantee that both the modules contain identical contents. Modules with the same names have different contents.
For example, core::panic exposes ZERO functions while std::panic exposes around 9 functions.
Is the Core really dependency free?
A dependency-free library is a library that does not depend on any other external library or file. It is a library that is complete just by itself.
The core library is NOT fully dependency free. It just depends on VERY FEW external definitions.
The compiled core code typically contains undefined linker symbols. It is up to the programmer to provide extra libraries that contain the definitions of those undefined symbols.
So there you go... Core is not 100% dependency-free.
The undefined symbols include :
- Six Memory routine symbols :
memcopy,memmove,memset,memcmp,bcmp,strlen. - Two Panic symbols:
rust_begin_panic,eh_personality
What are these symbols?
We will discuss the above symbols in the next 2 sub-chapters
Panic Symbols
Disclaimer: The author is not completely versed with the internals of panic. Improvement contributions are highly welcome, you can edit this page however you wish.
The core library requires the following panic symbols to be defined :
rust_begin_paniceh_personality
Before we discuss why those symbols are needed, we need to understand how panicking happens in Rust.
To understand panicking, please read this chapter from the rust-dev-guide book.
It would also be nice to have a copy of the Rust source-code so that you can peek into the internals of both core::panic and std::panic.
But before, you read those resources... let me try to explain panicking.
Understanding panic from the ground up.
Panics can occur explicitly or implicitly. If this statement does not make sense, read this Rust-book-chapter.
We will deal with explicit panics for the sake of uniformity and simplicity. Explicit panics are invoked by the panic!() macro.
When the Rust language runtime encounters a panic! macro during program execution, it immediately documents it. It documents this info internally by instantiating a struct called Location. location stores the path-name of the file containing panic!(), the faulty line and the exact column of the 'source token parser'.
Here is the struct definition of Location:
#![allow(unused)] fn main() { pub struct Location<'a> { file: &'a str, line: u32, col: u32, } }
The Rust-runtime then looks for the panic message that will add more info about the panic. Most of the time, that message is declared by the programmer like shown below. Sometimes no message is provided.
#![allow(unused)] fn main() { let x = 10; panic!("panic message has been provided"); panic!(); /*panic message has NOT been provided*/ }
The runtime then takes the message and the location and consolidates them by putting them as fields in a new instance of struct PanicInfo. Here is the internal description of the PanicInfo :
#![allow(unused)] fn main() { pub struct PanicInfo<'a> { payload: &'a (dyn Any + Send), message: Option<&'a fmt::Arguments<'a>>, // here is the panic message, as you can see...it is optional location: &'a Location<'a>, // here is the location field, it is not optional can_unwind: bool, force_no_backtrace: bool, } }
Now that the rust-runtime has an instance of PanicInfo, it moves on to either one of these two steps depending on the circumstaces:
- It passes the
PanicInfoto the function tagged by a#[panic_handler]attribute - It passes the
PanicInfoto the function that has been set byset_hookortake_hook
If you are in a no-std environment, option 1 is taken.
If you are in a std-environment, option 2 is taken.
The #[panic_handler] attribute and panic hook
The panic_handler is an attribute that tags the function that gets called after PanicInfo has been instantiated AND before the start of either stack unwinding or program abortion.
The above ☝🏾 statement is heavy, let me explain.
When a panic happens, the aim of the sane programmer is to :
- capture the panic message and panic location (file, line, column).
- maybe print the message to the
stderror to some external display - Recover the program to a stable state using mechanisms like
unwrap_or_else - Terminate the program safely if the panic is unrecoverable.
Step 1
The Runtime automatically does for you step one by creating PanicInfo.
Step 2:
It is then up to the programmer to define a #[panic_handler] function that consumes the PanicInfo and implement step 2.
You can do something like this:
#![allow(unused)] fn main() { #[panic_handler] fn my_custom_panic_handler (_info: &PanicInfo) -> !{ println!("panic message: {}", _info.message()); // print message to stdout println!("panic location: file: {}, line: {}". info.location.file(), info.location.line()); loop{} } }
If you are in an std environment, implementing step 2 is optional. This is because the std library already defines a default function called panic_hook that prints the panic message and location to the stdout.
This means that if you define a #[panic_handler] function in an std environment, you will get a duplication compilation error. A program can only have one #[panic_handler].
The only way to define a new custom panic_hook in an std environment is to use the set_hook function.
Step 3 & 4:
Both the panic_hook and the #[panic_handler] function transfer control to a code block called panic-runtime. There are two kinds of panic-runtimes provided by rust.
- Panic-unwind runtime
- panic-abort runtime
The programmer has the option of choosing one of the two options before compilation. In a normal std environment, panic-unwind runtime is usually the default.
So what are these?
panic-abort is a code block that causes the panicked program to immediately terminate. It leaves the stack occupied in hope that the kernel will take over and clear the stack. panic-abort does not care about safe program termination.
panic-unwind runtime on the other hand cares about recovery, it will free the stack frame by frame while looking for a function that can act as a recoveror. On worst case, it will not find a reovery function and it will just safely terminate the program by clearing the stack and releasing used memory.
So if you want to recover from panics, your bet would be to choose the panic-unwind runtime as your runtime of choice.
So ... How is recovery implemented?
Panic Recovery
As earlier mentioned, when a panic-worthy line of code gets executed, the language runtime itself creates an instance of Location and Message and eventually creates an instance of PanicInfo or PanicHookInfo. That is why you as the programmer have no way to construct your own instance of PanicInfo. It is something created at runtime by the language runtime.
The language runtime then passes a reference of the PanicInfo to the #[panic_handler] or panic_hook.
The panic hook and #[panic_handler] do their thing and eventually call either of the 2 panic runtimes.
Hope we are on the same page till there.
Now that we are on the same page, we need to introduce some new terms...
catch_unwind and unwinding-handlers
The aim of the panic-unwind runtime is to achieve the following:
- deallocate the stack upwards, frame by frame.
- For every frame deallocated, it records that info as part of the Backtrace.
- It continuously hopes that it will eventually meet an
unwinding-handlerfunction frame that will make it stop the unwinding process
If the panic-unwind finally meets a handler, it stops unwinding and transfers control to the Handler. It also hands over the PanicInfo to that handler function.
So what are handler functions?
Handler functions are functions that have the ability to stop the unwinding, consume the PanicInfo created by a panic and do some recovery magic.
These handlers come in different forms. One of these forms is the catch_unwind function.
catch_unwind is a function provided by std that acts as a "bomb container" for a funtion that may panic.
This function takes in a closure that may panic and then runs that closure as an inner child. If the closure panics, catch_unwind() returns Err(panic_message). If the closure fails to panic, catch_unwind returns an Ok(value).
Below is a demo of a catch_unwind function in use:
#![allow(unused)] fn main() { use std::panic; let result = panic::catch_unwind(|| { println!("hello!"); }); assert!(result.is_ok()); let result = panic::catch_unwind(|| { panic!("oh no!"); }); assert!(result.is_err()) }
catch-unwind is not the only unwinding-handler, there are other implicit and explicit handlers. For example, Rust implicitly sets handlers that encompass each thread by default such that if a thread panics, it will unwind its stack till it meets either an explicit internal handler OR it eventually meets the implicit thread_handler inserted by the compiler during thread instantiation. The recoery mechanism implemented by rust in such a case is to return Result(_) to the parent thread.
What does it mean to catch a panic?
Catching a panic means preventing a program from completely terminating after a panic by either implicitly or explicitly adding handlers within your code.
You can add implicit handlers by enclosing dangerous functions in isolated threads and count on the language runtime to insert unwinding-handlers for you.
You can add an explicit handler by pasing a dangerous functions as an argument to a catch_unwind function
Unwind Safety
UnwindSafe is a marker trait that indicates whether a type is safe to use after a panic has occurred and the stack has unwound. It ensures that types do not leave the program in an inconsistent or undefined state after a panic, thus helping maintain safety in Rust's panic recovery mechanisms.
(undone: limited knowledge by initial author, contribution needed)
>My knowledge on unwind-safety ends there.
Any contributor can focus on showing the UnwindSafe, RefUnwindSafe and AssertUnwindSafe markers in action. You can even show where they fail (thank you in advance)
That's all concerning panic recovery, go figure out the rest.
Panic_impl and Symbols
During the compilation process, both the #[panic_handler] and panic_hook usually get converted into a language item called panic_impl.
In Rust, "language items" are special functions, types, and traits that the Rust compiler needs to know about in order to implement certain fundamental language features. These items are usually defined in the standard library (std) or the core library (core) and are marked with the #[lang = "..."] attribute.
Think of language items as 'tokens that affect the functionality of the compiler'.
Below is the signature of panic_impl, I hope you can see the direct similarity btwn #[panic_handler] and panic_impl
#![allow(unused)] fn main() { extern "Rust" { #[lang = "panic_impl"] fn panic_impl(pi: &PanicInfo<'_>) -> !; } }
The reason this conversion takes place is because the language designers wanted to introduce indirection for the sake of making std::panic to have the ability to override core::panic during compilation.
As the compilation levels go further, panic_impl gets compiled into the symbol rust_begin_panic. In the final binary file, the panic_impl symbol is absent.
I guess now you understand what the core library demands from you when it says that you need to provide a definition of the rust_begin_panic symbol.
eh_personality
As for the eh_personality symbol, is not really a symbol. It is a languge item.
The eh_personality language item marks a function that is used for implementing stack unwinding. By default, Rust uses unwinding to run the destructors of all live stack variables in case of a panic. This ensures that all used memory is freed and allows the parent thread to catch the panic and continue execution. Unwinding, however, is a complicated process and requires some OS-specific libraries (e.g. libunwind on Linux or structured exception handling on Windows)
If you choose to use the panic-unwind runtime, then you must define the unwinding function and tag it as the eh_personality language item
Memory Symbols
The memory symbols required by the core library are six:
memcopy,memmove,memset,memcmp,bcmp,strlen.
Rust codegen backends generate code that usually reference the above six functions.
It is up to the programmer to provide definitions of the above six functions. You need to provide them in a file containing the assembly code or machine code for your specific processor.
The definitions of memcpy, memmove, memset, memcmp, bcmp, and strlen are listed as requirements because they represent commonly used memory manipulation and string operation functions that are expected to be available for use by generated code in certain contexts. While they are not strictly required for every Rust program, they are often relied upon by code generated by Rust's compiler, especially in situations where low-level memory manipulation or string operations are necessary.
Here are some reasons why these definitions are listed as requirements:
-
Interoperability with C Code: Rust often needs to interoperate with existing C libraries or codebases. These C libraries commonly use functions like memcpy, memset, and strlen. Therefore, ensuring that Rust code can call these functions or be called from C code requires that their definitions are available.
-
Compiler Optimizations: Even if a Rust program doesn't explicitly call these functions, the Rust compiler may internally use them as part of optimization passes. For example, when optimizing memory accesses or string manipulations in Rust code, the compiler may choose to use these functions or their equivalents to generate more efficient machine code.
Disclaimer: The author is not completely versed with the internals of panic. Improvement contributions are highly welcome, you can edit this page however you wish. (undone)
here is a snippet from core documentation in concern of memory symbols:
memcpy,memmove,memset,memcmp,bcmp,strlen- These are core memory routines which are generated by Rust codegen backends. Additionally, this library(core lib) can make explicit calls tostrlen. Their signatures are the same as found in C, but there are extra assumptions about their semantics: Formemcpy,memmove,memset,memcmp, andbcmp, if thenparameter is 0, the function is assumed to not be UB, even if the pointers are NULL or dangling. (Note that making extra assumptions about these functions is common among compilers: clang and GCC do the same.) These functions are often provided by the system libc, but can also be provided by the compiler-builtins crate. Note that the library does not guarantee that it will always make these assumptions, so Rust user code directly calling the C functions should follow the C specification! The advice for Rust user code is to call the functions provided by this library instead (such asptr::copy).
Practicals
Now that you know a little bit about the core library, we can start writing programs that depend on core instead of std.
This chapter will take you through the process of writing a no-std program.
We will try our very best to do things in a procedural manner...step by step... handling each error slowly.
If you do not wish to go through these practicals(1,2 & 3) in a stepwise fashion, you can find the complete no-std template here
Step 1: Disabling the Std library
Go to your terminal and create a new empty project :
cargo new no_std_template --bin
Navigate to the src/main.rs file and open it.
By default, rust programs depend on the standard library. To disable this dependence, you add the '#[no_std]` attribute to your code. The no-std attribute removes the standard lobrary from the crate's scope.
#![no_std] // added the no-std attribute at macro level (ie an attribute that affects the whole crate) fn main(){ println!("Hello world!!"); }
If you build this code, you get 3 compilation errors.
- error 1: "cannot find macro
printlnin this scope" - error 2: "
#[panic_handler]function required, but not found" - error 3: "unwinding panics are not supported without std"
You can run this code by pressing the play button found at the top-right corner of the code block above. Or you can just write it yourself and run it on your local machine.
Step 2: Fixing the first Error
The error that we are attempting to fix is...
# ... snipped out some lines here ...
error: cannot find macro `println` in this scope
--> src/main.rs:3:5
|
3 | println!("Hello, world!");
| ^^^^^^^
# ... snipped out some lines here ...
The println! macro is part of the std library. So when we removed the std library from our crate's scope using the #![no_std] attribute, we effectively made the std::println macro to also go out of scope.
To fix the first error, we either...
- Stop using
std::printlnin our code - Define our own custom
println - Bring
stdlibrary back into scope.(Doing this will go against the main aim of this chapter; to write a no-std program)
We cannot choose option 3 because the aim of this chapter is to get rid of any dependence on the std library.
We could choose option 2 but implementing our own println will be cost us unnecessary hardwork. Right now we just want to get our no-std code compiling... For the sake of simplicity, we will not choose option 2. We will however write our own println in a later chapter.
So we choose the first option, we choose to comment out the line that uses the proverbial println.
This has been demonstrated below.
#![no_std] fn main(){ // println!("Hello world!!"); // we comment out this line. println is indeed undefined }
Only two compilation errors remain...
Fixing the second and third compilation errors
This is going to be a short fix but with a lot of theory behind it.
To solve it, we have to understand the core library requirements first.
The core library functions and definitions can get compiled for any target, provided that the target provides definitions of certain linker symbols. The symbols needed are :
- memcpy, memmove, memset, memcmp, bcmp, strlen.
- rust_begin_panic
- rust_eh_personality (this is not a symbol, it is actually a language item)
In other words, you can write whatever you want for any supported ISA, as long as you link files that contain the definitions of the above symbols.
1. memcpy, memmove, memset, memcmp, bcmp and strlen symbols
These are all symbols that point to memory routines.
You need to provide to the linker the ISA code that implements the above routines.
When you compile Rust code for a specific target architecture (ISA - Instruction Set Architecture), the Rust compiler needs to know how to generate machine code compatible with that architecture. For many common architectures, such as x86, ARM, or MIPS, the Rust toolchain already includes pre-defined implementations of these memory routines. Therefore, if your target architecture is one of these supported ones, you don't need to worry about providing these definitions yourself.
However, if you're targeting a custom architecture or an architecture that isn't directly supported by the Rust toolchain, you'll need to provide implementations for these memory routines. This ensures that the generated machine code will correctly interact with memory according to the specifics of your architecture.
2. the rust_begin_panic symbol
This symbol is used by Rust's panic mechanism, which is invoked when unrecoverable errors occur during program execution. Implementing this symbol allows the generated code to handle panics correctly.
You could say that THIS symbol references the function that the Rust runtime calls whenever a panic happens.
This means that you have to...
- Define a function that acts as the overall panic handler.
- Put that function in a file
- Link that file with your driver code when compiling.
For the sake of ergonomics, the cool rust developers provided a 'panic-handler' attribute that you can attach to a divergent function. You do not have to do all the linking vodoo. This has been demonstrated later on... do not worry if this statement did not make sense.
You can also revisit the subchapter on panic symbols to get a clear relationship between the rust_begin_panic symbol and the #[panic_handler] attribute.
3. The rust_eh_personality
When a panic happens, the rust runtime starts unwinding the stack so that it can free the memory of the affected stack variables. This unwinding also ensures that the parent thread catches the panic and maybe deal with it.
Unwinding is awesome... but complicated to implement without the help of the std library. Coughs in soy-dev.
The rust_eh_personality is not a linker symbol. It is a language item that points to code that defines how the rust runtime behaves if a panic happens : "does it unwind the stack? How does it unwind the stack? Or does it just refuse to unwind the stack and instead just end program execution?
To set this language behaviour, we are faced with two solutions :
- Tell rust that it should not unwind the stack and instead, it should just abort the entire program.
- Tell rust that it should unwind the stack... and then offer it a pointer to a function definition that clearly implements the unwinding process. (we are soy-devs, this option is completely and utterly off the table!!)
Step 3: Fixing the second compiler error
The remaining errors were ...
error: `#[panic_handler]` function required, but not found
error: language item required, but not found: `eh_personality`
|
= note: this can occur when a binary crate with `#![no_std]` is compiled for a target where `eh_personality` is defined in the standard library
= help: you may be able to compile for a target that doesn't need `eh_personality`, specify a target with `--target` or in `.cargo/config`
error: could not compile `playground` (bin "playground") due to 2 previous errors
This is our second error...
error: `#[panic_handler]` function required, but not found
This is our third...
error: language item required, but not found: `eh_personality`
Just like you guessed, the second error occured because the 'rust_begin_panic symbol' has not been defined. We solve this by pinning a '#[panic_handler]' attribute on a divergent function that takes 'panicInfo' as its input. This has been demonstrated below. A divergent function is a function that never returns.
#![no_std] use core::panic::PanicInfo; #[panic_handler] // you can name this function any name...it does not matter. eg the_coolest_name_in_the_world // The function takes in a reference to the panic Info. // Kid, go read the docs in core::panic module. It's short & sweet. You will revisit it a couple of times though fn default_panic_handler(_info: &PanicInfo) -> !{ loop { // function does nothing for now, but this is where you write your magic // // This is where you typically call an exception handler, or call code that logs the error or panic messages before aborting the program // The function never returns, this is an endless loop... The panic_handler is a divergent function } } fn main(){ // println!("Hello world!!"); }
Would you look at that... if you compile this program, you'll notice that the second compilation error is gone!!!
Step 4: Fixing the Third Error
The third error states that the 'eh_personality' language item is missing.
It is missing because we have not declared it anywhere... we haven't even defined a stack unwinding function. So we just configure our program to never unwind the stack, that way... defining the 'eh_personality' becomes optional.
We do this by adding the following lines in the cargo.toml file :
# this is the cargo.toml file
[package]
name = "driver_code"
version = "0.1.0"
edition = "2021"
[profile.release]
panic = "abort" # if the program panics, just abort. Do not try to unwind the stack
[profile.dev]
panic = "abort" # if the program panics, just abort. Do not try to unwind the stack
Now ... drum-roll... time to compile our program without any errors....
But then ... out of no-where, we get a new diferent error ...
error: using `fn main` requires the standard library
|
= help: use `#![no_main]` to bypass the Rust generated entrypoint and declare a platform specific entrypoint yourself, usually with `#[no_mangle]`
Aahh errors... headaches...
But at least it is a new error. 🤌🏼🥹
It's a new error guys!! 🥳💪🏼😎
Practicals : Part 2
At the end of the last sub-chapter, we got the following error :
error: using `fn main` requires the standard library
|
= help: use `#![no_main]` to bypass the Rust generated entrypoint and declare a platform specific entrypoint yourself, usually with `#[no_mangle]`
Before we solve it, we need to cover some theory...
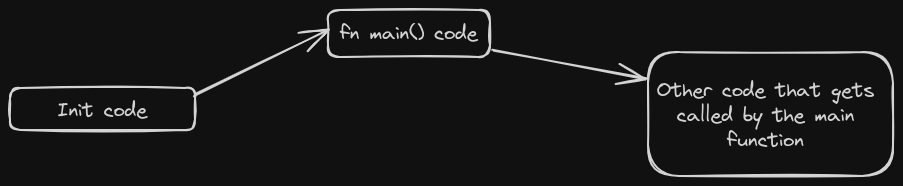
Init code
'init code' is the code that gets called before the 'main()' function gets called. 'Init code' is not a standard name, it is just an informal name that we will use in this book, but I hope you get the meaning here. Init_code is the code that gets executed in preparation for the main function.
To understand 'init code', we need to understand how programs get loaded into memory.
When you start your laptop, the kernel gets loaded into memory.
When you open the message_app in your phone, the message_app gets loaded into memory.
When you open VLC media player on your laptop, the VLC media player gets loaded into memory (The RAM).
To dive deeper into this loading business, let's look at how the kernel gets loaded.
Loading the kernel.
When the power button on a machine(laptop) is pressed, the following events occur. (this is just a summary, you could write an entire book on kernel loading):
-
Power flows into the processor. The processor immediately begins the fetch-execute cycle. Except that the first fetch occurs from the ROM where the firmware is.
-
So in short, the firmware starts getting executed. The firmware performs a power-on-self test.
-
The firmware then makes the CPU to start fetching instructions from the ROM section that contains code for the
primary loader. The primary loader in this case is a program that can copy another program from ROM and paste it in the RAM in an orderly pre-defined way. By orderly way I mean ... it sets up space for the the stack, adds some stack-control code to the RAM(eg stack-protection code), and then loads up the different sections of the program that's getting loaded. If the program has overlays - it loads up the code that implements overlay control too.
Essentially, the loader pastes a program on the RAM in a complete way. -
The
primary loaderloads the Bootloader onto the RAM. -
The
primary loaderthen makes the CPU instruction pointer to point to the RAM section where the Bootloader got pasted. This results in the execution of the bootloader. -
The Bootloader then starts looking for the kernel code. The kernel might be in the hard-disk or even in a bootable usb-flash.
-
The Bootloader then copies the kernel code onto the RAM and makes the CPU pointer to point to the entry point of the kernel. An entry-point is the memory address of the first instruction for any program.
-
From there, the kernel code takes full charge and does what it does best.
-
The kernel can then load the apps that run on top of it... an endless foodchain.
Why are we discussing all these?
To show that programs run ONLY because these two conditions get fulfilled:
-
They were loaded onto either the ROM or the RAM in a COMPLETE way.
The word Complete in this context means that the program code was not copied alone; The program code was copied together with control code segments that deal with things like stack control and overlay-control. The action of copying 'control' code onto the RAM is part of Setting up the environment before program execution starts.In the software world, this control code is typically called runtime code.
-
The CPU's instruction pointer happened to point to the entry point of the already loaded program. An entry-point is the memory address of the first instruction for a certain program.
Loading a Rust Program
From the previous discussion, it became clear that to run a program, you have to do the following :
- load the program to a memory where the CPU can fetch from (typically the RAM or ROM.).
- load the runtime for the program into memory. The runtime in this case means 'control code' that takes care of things like stack-overflow protection.
- make the CPU to point to the entry_point of the (loaded program + loaded runtime)
A typical Rust program that depends on the std library is ran in exactly the same way. The runtime code for such programs includes files from both the C-runtime and the Rust Runtime.
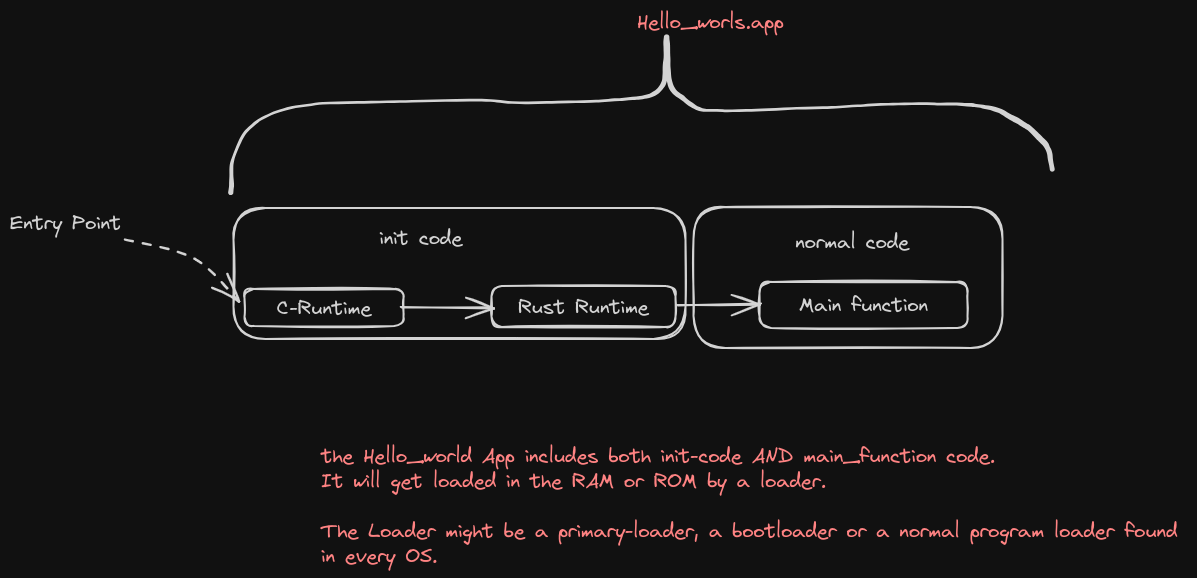
When a Rust program gets loaded into memory, it gets loaded together with the C and Rust runtimes.
The normal entry point chain
The normal entry point chain describes the order in which code gets executed and their respective entry-point labels.
In Rust the C-runtime gets executed first, then the Rust runtime and finally the normal code.
The entry_point function of the C-runtime is the function named _start.
After the C runtime does its thing, it transfers control to the Rust-runtime. The entrypoint of the Rust-runtime is labelled as a start language item.
The Rust runtime also does its thing and finally calls the main function found in the normal code.
And that's it! Magic!
During program execution, the instruction pointer occasionally jumps to appropriate Rust runtime sections. For example, during a panic, the instruction pointer will jump to the rust_begin_panic symbol that is part of the Rust runtime.
Understanding Runtimes
To understand exactly what the above two runtimes do, read these two chapters below. They are not perfect, but they are a good start.
In summary, the C-runtime does most of the heavy-lifting, it sets up ...(undone).
The Rust Runtime takes care of some small things such as setting up stack overflow guards or printing a backtrace on panic.
Fixing the Error
To save you some scrolling time, here is the error we are trying to fix.
error: using `fn main` requires the standard library
|
= help: use `#![no_main]` to bypass the Rust generated entrypoint and declare a platform specific entrypoint yourself, usually with `#[no_mangle]`
This error occurs because we have not specified the entrypoint chain of our program.
If we had used the std library, the default entry-point chain could have been chosen automatically ie the entry point could have been assumed to be the '_start' symbol that directly references the C-runtime entrypoint.
To tell the Rust compiler that we don’t want to use the normal entry point chain, we add the #![no_main] attribute. Here's a demo :
#![allow(unused)] #![no_std] #![no_main] // here is the new line. We have added the no_main macro attribute fn main() { use core::panic::PanicInfo; #[panic_handler] fn default_panic_handler(_info: &PanicInfo) -> !{ loop { /* magic goes here */ } } // main function has just been trashed... coz... why not? It's pointless }
But when we compile this, we get a linking error, something like this ...
error: linking with `cc` failed: exit status: 1
|
# some lines have been hidden here for the sake of presentability...
= note: LC_ALL="C" PATH="/home/k/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/x86_64-unknown-linux-gnu/bin:/home/k/.cargo/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin" VSLANG="1033" "cc" "-m64" "/tmp/rustcWMxOew/symbols.o" "/home/k/ME/Repos/embedded_tunnel/driver-development-book/driver_code/target/debug/deps/driver_code-4c11dfa3f10db3d0.f20457jvl65bh2w.rcgu.o" "-Wl,--as-needed" "-L" "/home/k/ME/Repos/embedded_tunnel/driver-development-book/driver_code/target/debug/deps" "-L" "/home/k/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/x86_64-unknown-linux-gnu/lib" "-Wl,-Bstatic" "/home/k/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/x86_64-unknown-linux-gnu/lib/librustc_std_workspace_core-9686387289eaa322.rlib" "/home/k/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/x86_64-unknown-linux-gnu/lib/libcore-632ae0f28c5e55ff.rlib" "/home/k/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/x86_64-unknown-linux-gnu/lib/libcompiler_builtins-3166674eacfcf914.rlib" "-Wl,-Bdynamic" "-Wl,--eh-frame-hdr" "-Wl,-z,noexecstack" "-L" "/home/k/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/x86_64-unknown-linux-gnu/lib" "-o" "/home/k/ME/Repos/embedded_tunnel/driver-development-book/driver_code/target/debug/deps/driver_code-4c11dfa3f10db3d0" "-Wl,--gc-sections" "-pie" "-Wl,-z,relro,-z,now" "-nodefaultlibs"
= note: /usr/bin/ld: /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/Scrt1.o: in function `_start':
(.text+0x1b): undefined reference to `main'
/usr/bin/ld: (.text+0x21): undefined reference to `__libc_start_main'
collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo (see https://doc.rust-lang.org/cargo/reference/build-scripts.html#cargorustc-link-libkindname)
This error occurs because the toolchain thinks that we are compiling for our host machine and therefore decides to use the default linker script targeting the host machine... which in this case happens to be a linux-mint machine with a x86_64 CPU.
The reason this is a problem is because that linker script references start files that reference undefined symbols like __libc_start_main and start.
To view the default linker script that gets used, you can follow these steps
To fix this error, we implement one of the following solutions :
- Specify a cargo-build for a triple target that has 'none' in its OS description. eg
riscv32i-unknown-none-elf. This is the easier of the two solutions, and it is the most flexible. - Supply a new linker script that defines our custom entry-point and section layout. If this method is used, the build process will still treat the host's triple-target as the compilation target.
If the above 2 possible solutions made complete sense to you, and you were even able to implement them, just skim through the next few sub-chapters as a way to humor yourself.
If they did not make sense, then you got some reading to do in the next immediate sub-chapters...
Don't worry, we will get to a point where our bare-metal code will run without a hitch... but it's a long way to go.
The next subchapters will be just theory...we'll fix the compiler error soon.
Cross-Compilation
Compilation is the process of converting high level code into low-level code. This typically involves converting source code into machine code. ie. converting text into zeroes-and-ones.
In less typical cases, you can convert high-level code into less-high-level code. eg Rust to LLVM-IR (Intermediate representation). Point is, compilation isn't always about translating source code into binary.
The compilation process for a single file roughly looks like this ...
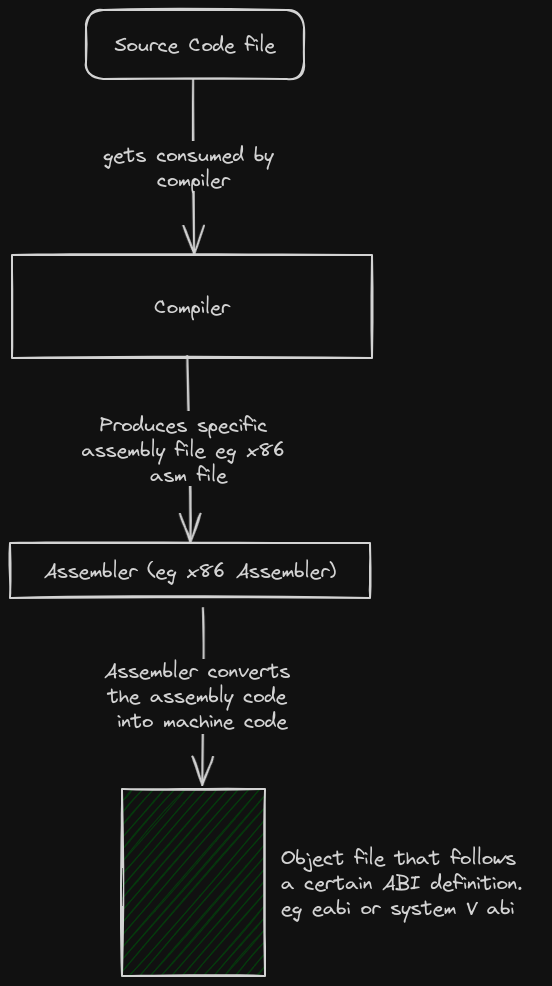
When multiple files need to get compiled together, the linker gets introduced :
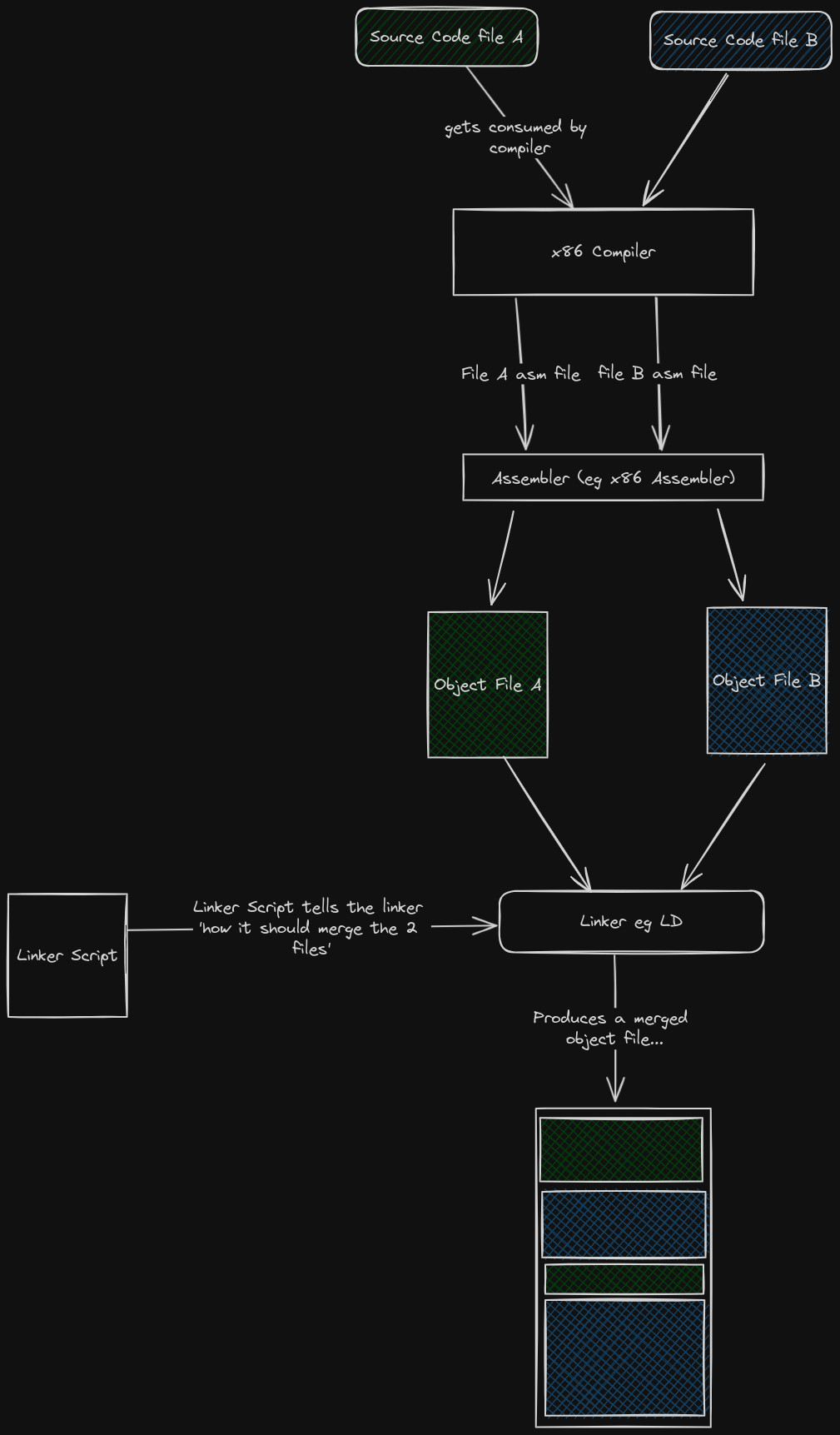
Before we discuss further, make sure you are conversant with the following buzzwords :
- Instruction Set Architecture (ISA)
- Application Binary Interface (ABI)
- Application Programming Interface (API)
- An Execution environment
- The host machine is the machine on which you develop and compile your software.
- The target machine is the machine that runs the compiled sotware. ie the machine that you are compiling for.
Target
If we are compiling program x to run on machine y, then machine y is typically referred to as the Target.
If we compile the hello-world for different targets, we may end up with object files that are completely different from each other in terms of file format and file content.
This is because the format and contents of the object file are majorly affected by the following factors :
-
The CPU Architecture of the target.
Each ISA has its own machine code syntax, semantics and encoding. This means that the add_function may be encoded as001in ISAxand as011in ISAy. So even if the instructions look identical, the object files end up having a different combination of zeroes and ones. -
The Vendor-specific implementations on both the software and hardware of the target machine. (undone: this sentence needs further explanations)
-
The Execution environment on which the compiled program is supposed to run on. In most cases the Execution environment is usually the OS. The execution environment affects the kind of symbols that get used in the object files. For example, a program that relies on the availability of a full-featured POSIX OS will have different symbols than those found in a NON-POSIX OS.
-
The ABI of the execution environment. The structure and content of the object file is almost entirely dependent on the ABI.
To find out how these 4 factors affect the object file, read here.
The above 4 factors were so influential to target files that people started describing targets based on the state of the above 4 factors. For example :
Target x86_64-unknown-linux-gnu means that the target machine contains a x86 CPU, the vendor is unknown and inconsequential, the execution environment is an Operating system called Linux, the execution environment can interact with object files ONLY if they follow the GNU-ABI specification.
Target riscv32-unknown-none-elf means that the target machine contains a Riscv32 CPU, the vendor is unknown and inconsequential, the execution environment is nothing but bare metal, the execution environment can interact with object files ONLY if they follow the elf specification.
People usually call these target specifications triple targets...
Don't let the name fool you, some names contain 2 parameters, others 4 ... others 5. The name Triple-target is a misnomer. Triple-targets don't refer to 3-parameter names alone.
The software world has a naming problem...once you notice it, you see it everywhere. For example, what is a toolchain? Is it a combination of the compiler, linker and assembler? Or do we throw in the debugger? or maybe even the IDE? What is an IDE?? Is a text Editor with plugins an IDE?? You see? Madness everywhere!! Naming things is a big problem.
Why are triple-target definitions important? --> Toolchain Setup
Because they help you in choosing and configuring your compiler, assembler and linker in such a way that allows you to build object files that are compatible with the target.
For example, if you were planning to compile program x for a x86_64-unknown-linux-gnu target....
- You would look for a x86_64 compiler, and install it. A riscv compiler would be useless. An ARM compiler would also be useless.
- You would look for a x86_64 assembler, and install it. Any other assembler would be useless.
- You would then look for system files that were made specifically for the Linux kernel. For example, system files with an implementation of the C standard library such as glibc, newlib and musl.
- You would look for a linker that can process and output GNU-ABI-compliant object files
- You would then write a linker script that references symbols found in the linux-specific system files. That linker script should also outline the layout of an object file that the kernel can load eg Elf-file layout.
- You would then configure all these tools and libraries to work together.
This is a lot of work and stress. Let us call this problem the toolchain-setup problem. This is because the word toolchain typically refers to the combination of tools such as the Compiler, linker, assembler, debugger and object-file manipulation tools.
Rust has a solution to this toolchain-setup problem.
Enter target specification
Rust solves the toolchain-setup problem by providing a compiler feature called target specification. This feature allows you to create object files for any target architeture that you specify. The compiler will automatically take care of choosing a linker, providing a linker script, finding the right system-files and take care of other configurations.
If you had installed your Rust toolchain in the normal fashion... ie. using rustup, then there is a high chance that your compiler has the ability to produce object files for your host-machine's triple-target ONLY.
To see the target-architecture AND triple-target name of your machine, run the following commands :
uname --machine # This outputs your machine's ISA
# this only works for linux machines.
# the author had no idea how to do it in Windows & MacOS. Sorry.
gcc -dumpmachine # This command outputs the triple-target
# only works if you have gcc installed
To see which triple-targets your rust compiler can produce object files for, run the following command :
rustup target list --installed
You can make the compiler to acquire the ability to compile for an new additional triple-target by running the command below :
# rustup target add <new-triple-target-name>
rustup target add riscv32imc-unknown-none-elf
# To see the possible triple-target names that could be used in the command above, run this command
rustup target list
You can then make the compiler to produce an object file for a specific target using the command below :
# cross-compile for any target whose target has already been installed
# The syntax of the command is :
# cargo build <name_of_your_codebase> --target=<name_of_your_triple_target>
cargo build hello-world --target=riscv32imc-unknown-none-elf
Cross-compilation
Cross-compilation is the act of compiling a program for a target machine whose triple-target specification is different from the triple-target specification of the host machine.
We achieve cross-compilation in Rust by using the Target-specification compiler feature discussed above.
Making cross-compilation easier with cargo
Example case :
Assuming that we are compiling a program on a x86_64-unknown-linux-gnu host machine and that we intend to run the program on a riscv32-unknown-none-elf target machine.
We could use the command-line like this...
cargo build --target=riscv32-unknown-none-elf
But this would require us to repeat a lengthy command each time we compile our code. To make work easier, we could instruct cargo to always compile for a certain triple-target within our cargo project.
This is achieved by modifying the .cargo/config.toml file
# This is the .cargo/config.toml file
[build]
target = riscv32-unknown-none-elf
So each time you want to build the project, you run the usual command ...
cargo build
Cargo is an awesome tool, learn more about it in the Cargo Book
Understanding Cross-compilation
What we have covered in this chapter is "How to cross-compile in Rust".
We have not covered the internals of cross-compilation. A good place to start would be to understand a bit about the LLVM project.
LLVM
LLVM is a huge topic on its own, you can read the docs at the LLVM's main website or check out the alternative resources listed at the bottom of the page.
LLVM is a set of modular Toolchain components such as Compilers, optimizers, linkers, assemblers, code-generators.
Originally, it began as a Compiler-builder/ compiler-framework for any language...
But now it has transformed from being just a compiler-framework, to being a toolchain comprising of many components with different functions.
The unique features across the board are that :
- The components can be tweaked to suit different languages and execution environments.
- The components are independent of each other.
LLVM components
-
LLVM core libraries : the core libraries include an IR-optimizer and a couple of pre-made code generators for popular CPUs. This module does not include an IR-to-machinecode code-generator.
-
Clang: this is a compiler front-end for C, C++ and Objective C. It is not a full-fledged compiler. It converts source code into an AST, does semantic analysis and typechecking before converting it into LLVM-IR. Clang DOES NOT do optimization, code generation or linking.
-
LLDB: this is the LLVM Debugger
-
LLD: this is the LLVM linker
-
libclc: an implementation of the OpenCL standard library. (OpenCL == Open Computer Language)
Learning Resources.
- My First Language Frontend with LLVM Tutorial.
- Rust tutorial that goes all the way but is curently deprecated
- Rust tutorial that cuts out the frontend part and assumes you know LLVM. (uses pest and inkwell libraries)
- llvm IR explained by McYoung
Cranelift
This is an undone chapter.
You can go through the resources below :
- general documentation
- IR-reference
- Awesome blog on cranelift internals: part1, part2, part3, part4
- A primer on Code-generation using cranelift
- rustc-codegen-cranelift
Linkers and Linking
Linking is a VERY fundamental topic.
It is best to learn it slowly and in full from the docs listed below.
For this reason, this book will not spoil or water-down the purity of the linking docs.
Note-worthy docs
- Start with this 3-minute video demonstrating the role of the linker from a high level.
- You can read the first 3 chapters of "Loaders and Linkers" by John R. Levine
- Then move to this doc. It is gentle, covers the basics of LLD and its short.
- And finally finish it with this more detailed docs. The two most important pages there are on memory description and memory abstraction.
You might be tempted to read these other books and tutorials. They go deep. They do not focus on LLD
- Loaders and Linkers by John R. Levine
- Blog : "Beginner's Guide to Linkers" by lurklurk
- https://lwn.net/Articles/276782/
linkers in Rust
There are many linkers in existence. However the two dominant linkers are :
- The LD linker (also called the GNU linker)
- The LLD linker (also called the LLVM linker)
The Rust toolchain is built using the LLVM toolchain, so it uses the LLVM linker by default. You can however configure it to use the GNU linker after some tweaks to the cargo configuration file.
The GNU linker and the LLVM linker have two subtle and important differences have been listed below.
1. Automatic linker-script generation.
The GNU linker ALWAYS requires a manually-defined linker script to function while the LLD (the LLVM linker) doesn't always require a manually-defined linker script to function.
In many cases, LLD can automatically generate linker scripts internally based on the specified triple-target, format, and other parameters specified before & during the linking process. This means that LLD can handle the linking process without requiring an explicit linker script provided by the user.
However, LLD does provide a way for users to specify custom linker scripts if needed. Users can pass a custom linker script to LLD using command-line options or configuration files, similar to how it's done with LD. This gives users flexibility in defining the linking behavior and organizing the output binary according to their specific requirements.
2. Cross linking and the existence of flavours
The GNU linker is compact and straight-foward. There is only one GNU linker. If you want to compile something into an elf, you supply the linker with an elf-generating linker script. If you need a wasm binary file, you supply it with a corresponding linker script.
This may seem simple at first, but writing a correct linker script is usually not an easy task. To solve this problem, the LLVM linker implemented the concept of linker-flavours.
The LLVM linker is not a monolith, it is made up of different specialized linkers that are typically called flavours. The flavours produce object files for specific targets ONLY.
For example, Let's say you want to produce a unix elf file, instead of writing a complex & erronous linker script, you could use the LD.LLD linker flavour and it will automatically generate an internal unix-elf-focussed script for you. This is what makes LLD a cross-linker by default.
There are currently 4 mainstream LLVM-linker flavours :
-
LD.LLD (unix) : specializes in generating object files and executables for Unix-like operating systems, such as Linux and FreeBSD. It supports formats like ELF (Executable and Linkable Format) and handles symbol resolution, linking libraries, and generating debug information specific to Unix environments.
-
ld64.lld (macOS) : specializes in producing object files and executables for macOS and other Apple platforms. It supports the Mach-O (Mach Object) file format used on macOS.
-
lld-link (Windows) : specializes in generating object files and executables for Windows-based systems. It supports the PE (Portable Executable) file format used on Windows, handles symbol resolution, and integrates with Windows-specific tools and libraries for linking applications and generating executables compatible with the Windows environment.
-
wasm-ld (WebAssembly) : This flavour is a work in progress. It specializes in producing WebAssembly (Wasm) modules and executables that follow wasm specifications.
Implications of those two subtle differences
-
It becomes easy to make the Rust toolchain to be able to compile and link for new targets. The
rustup target addcommand literally does this. -
Declaring linker scripts becomes optional.
To view the defult lld flavour of a supported target, run the following command :
# Replace `riscv32i-unknown-none-elf` with a target of your liking
rustc -Z unstable-options --target riscv32i-unknown-none-elf --print target-spec-json
Feedback :
{
"arch": "riscv32",
"atomic-cas": false,
"cpu": "generic-rv32",
"crt-objects-fallback": "false",
"data-layout": "e-m:e-p:32:32-i64:64-n32-S128",
"eh-frame-header": false,
"emit-debug-gdb-scripts": false,
"features": "+forced-atomics",
"is-builtin": true,
"linker": "rust-lld", # HERE is the linker name... it could have been something like ld
"linker-flavor": "gnu-lld", # HERE is the linker Flavour
"llvm-target": "riscv32",
"max-atomic-width": 32,
"panic-strategy": "abort",
"relocation-model": "static",
"target-pointer-width": "32"
}
Other notes
-
overlay manager
-
dynamic linking
-
Role of linker in program loading
-
emphasis on overlay management was slowed down by the rise of bigger, cheaper and faster memories/RAM.
-
Hardware-assisted relocation and virtual addresses made overlay management easiers
-
new difficulties in creating linkers
- support dynamic linking
- support shared libraries
- support name mangling
- support debugging of both running and dynamic code
- support overlays
- support compiler-scheduled memory accesses (for improved cache performance)
- support all types of optimizations. global program optimization. The linker is the first program that will see the entire program as one unit. It is expected to use this to its advantage and introduce substancial improvements. It is also the program that can do memory optimizations
- Memory mapped programs : (have no direct access to shared libraries)
- Instruction re-ordering
-
The linker should not alter the behaviour of the intended program
-
As systems became more complex, they called upon linkers to do more and more complex name management and address binding.
What of relinking symbols?
What of debugging symbols?
Practicals - part 3
Well, that was a long break.
Last time in practicals 2, we got the following compilation error before we had to learn about cross-compilation and linking.
error: linking with `cc` failed: exit status: 1
|
# some lines have been hidden here for the sake of presentability...
= note: /usr/bin/ld: /usr/lib/gcc/x86_64-linux-gnu/11/../../../x86_64-linux-gnu/Scrt1.o: in function `_start':
(.text+0x1b): undefined reference to `main'
/usr/bin/ld: (.text+0x21): undefined reference to `__libc_start_main'
collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo (see https://doc.rust-lang.org/cargo/reference/build-scripts.html#cargorustc-link-libkindname)
Analyzing the error
Using the cross-compilation and linking knowledge, we can dissect the above compilation error.
# ...
error: linking with `cc` failed: exit status: 1
# ...
cc stands for C Compiler. It looks like some linking error occured while the C compiler was compiling some files in our codebase. Why the hell is Rust calling a C compiler? Which files need to be compiled using the C compiler?
Well, if we scroll to some lower sections of the error, we see the crt1.o file mentioned. This is an object file that usually gets used as part of the C-runtime. (it must have been written in C, this must be the reason why our compilation process had to summon the C-compiler) - mystery 1 solved.
Mystery two: Why are C runtime files getting involed in our code-base even after we had added the #![no_main] attribute?
The C runtime files got involved because the Rust compiler still thinks that we are compiling for the host's triple-target. The reason why it still thinks that is because we used the command cargo build instead of cargo build --target=<a_different_target>
Compiling for the host's triple-target means that the linker will by default use a pre-defined linker-script that had been made specifically for the host. In our case, the pre-defined linker-script had information relating to the C runtime and that is how the C-runtime files got involved in the drama.
To fix this error, we have to stop the usage of that linker-script that has C-runtime affiliations.
We can implement one of the following solutions:
Solution 1. Provide our very own linker-script that does not have affiliations to the C-runtime files (also called start files).
Solution 2. Instruct the linker to stop including C-runtime file symbols to our object files.
Solution 3. We can stop compiling for any target that has a C-affiliated-linker-script and instead, only compile for targets that have linker-scripts that do not reference the C-runtime. All triple-targets that have Operating systems specified are almost assured to call the C-runtime. All triple-targets that do not have the operating-system specified are less likely to call the C runtime. In short, triple-targets that use the std library are out of our radar.
Solution 1.
Solution 1 is about writing our own linker-script as a solution since a manual linker-script usually overides the default auto-generated script.
Try to implement this on your own. You can view the linker-script used in the no-std-template to get some ideas.
Solution 2.
Solution 2 is achieved by running the following command.
cargo rustc -- -C link-arg=-nostartfiles # learn more about these commands by reading the Cargo and Rustc books
Solution 3.
Solution 3 can be implemented by running the command below :
cargo build --target=riscv32i-unknown-none-elf
# You can replace `riscv32i-unknown-none-elf` with a target that you have already installed
# The target here should have the value 'none' in place of the Operating system
The point of Solution 3 is to build for bare-metal targets only.
FINALLY
And if you compile your program, it compiles without any errors.
That's it! A bare-metal program that literally does nothing, just boiler-plate.
Quite anti-climatic.
Now you've learnt how to build bare-metal programs. You are yet to learn bare-metal debugging, functional-testing, performance-testing and monitoring. Those chapters will be covered later on.
For now, the next chapters will be about the UART. We are so far away from writing UART code. It's a long way off, but we'll get there slowly.
Binary File Inspection in Rust
We will be dealing with binary files in our development, so it's better to get comfortable with them.
For an in depth understanding, just read the first 2 chapters of the book recommended at the bottom of the page.
Oh well, here goes the shallow explanation for those who won't read the book...
What's a binary file?
A binary file is a file filled with zeroes and ones. End of story.
The 0s and 1s might be machine code or any other data that can be encoded to binary.
That's it.
Types of binary files
Any file can contain a bunch of 0's and 1's but there are some that contain meaningful combinations of 0's and 1's.
There're many kinds of binary files but we'll just cover binary files that are relevant to us.
-
An executable binary is a binary file that gets produced by a compilation toolchain, this file is fully executable and self-contained. (eg main.out on linux)
-
A Relocatable object file is a specific type of binary file produced by a compiler or assembler. It contains machine code, but it is not a complete executable program. Instead, it represents a single translation unit (e.g, a compiled source file) that needs to be linked with other object files and libraries to create a final executable. (eg lib.o). It is called relocatable because it contains symbols that references memory addresses that are NOT FINAL.
-
A dynamic binary file is a shared library produced by a compilation toolchain too. It is fully compiled and linked, but it is designed to be loaded at runtime rather than being fully self-contained. (e.g., .so on Linux, .dll on Windows)
Binary File Formats
A bunch of 0's and 1's can be meaningless unless they are structured, parsable and maybe executable.
Binary file formats define the structure and encoding of data within a binary file. These formats specify how sequences of bits and bytes are organized to represent different types of data such as executable code, images, or multimedia.
Common binary file formats include "Executable and Linkable Format (ELF)" for unix-like systems and "Portable Executable (PE)" for Windows programs, and various proprietary formats for firmware and custom applications. Understanding these formats is key to interpreting and manipulating binary data effectively.
You can read about Elf file format from specifications, for example, here are some ELF reference docs from the Linux Foundation.
Forget about Portable Executable (PE), we wont need it. You can read about it if you wanna.
Why would anyone want to inspect binary files?
People inspect and edit binary files for the same reasons why people inspect and edit source code files -- To improve a program's performance in terms of memory and time, to break it, to crack it, to secure it, to reverse engineer it, to have fun, to show off.
You can even get a Phd in Binary analysis because it's an entire software field on its own.
You may want to inspect binary files for whatever reason you may have... but in our case, we inspect them for the following reasons...
Why a firmware dev might want to inspect/edit binary files
- Firmware code uses a lot of MMIO programming that references registers and ROM specific addresses. Being able to inspect the binary helps in verifying and editing specific memory addresses.
- Sometimes you'll deal with memory constrained devices and you'd want to strip the binary, monitor, edit and discard certain binary sections just to reduce binary file size.
- Being that you may deal with custom formats of binary, you may have to deal with custom program loaders. Having a good grip over binary file manipulation would be ideal. For example, in a memory constrained device, you may want to create a new way for dynamically overlaying specific segments of the program at runtime.
- Sometimes you'll be dealing with firmware whose source code is unavailable... reverse engineering the binary file would be the game. Proprietary hardware & firmware is so common, this may leave you dealing with black-boxes during debugging.
- SECURITY. SECURITY. Mf SECURITY. Security is a messy job, you have to protect your firmware from binary-exploiters, so you have to be a good exploiter too. A never-ending tiresome game. On the other hand, you can decide to just ignore security because in real life, firmware devs respect each other's sweat. They understand how much the other dev went through, if they find a bug, they just holla the responsible dev... and the world becomes a better place, just flowers everywhere.
Tools for the job
Hex Editors
Hex editors are programs that can be used to inspect and edit binary files. They can deal with both static and running binary files.
Let me repeat that, there are hex editors that can view and edit running programs. So imagine all the magic you can do with this.
You can read about them here.
If you want to get started on hex editors, have a look at ImHex, it is
- opensource
- has a nice GUI
- has a good online support(libraries)
- Has many functionalities and is extensible
- has good documentation
- has an inbuilt Pattern Analysis Language that was inspired by C++ & Rust
- crossplatform
If you want something lightweight you can go with either :
- Bless (has a simple GUI)
- Hexyl (it's a CLI made in Rust)
CMD tools
There are other standard and battle-tested cmd tools that have existed since the 80's.
These are the real deals.
Most of them come pre-installed with your linux box. Here's an incomplete list :
- Readelf: Displays information about ELF files, such as section headers, segments and even does some disassembly. You can read its man pages from your command line
- Objdump: Provides detailed information about the contents of object files, including disassembly of the code sections.
- LLVM tools :
- llvm-nm : used in analyzing symbols and symbol tables in a binary file.
- llvm-objcopy : Copies and translates object files, allowing you to extract, manipulate, or strip specific sections of an object or binary file. It's often used to create stripped-down versions of binaries or firmware images.
- llvm-mca : llvm machine code performance analyzer
- objdump : inspects and disassembles binary files
- readobj : Displays low-level information about object files and executable files, such as headers, sections, and symbols. (similar to readelf except that it's more universal to other known binary file formats)
- llvm-size : analyze the size of different elements in the binary eg sections.
- llvm-strip : Removes symbols and debugging information from binary files, reducing their size
- GNU tools (look them up, they are mostly similar to LLVM tools)
The above info is shallow, you can access the manuals of each of the tools above and mess around with them.
Rust and LLVM-tools
Rust easily integrates with the LLVM-binary tools
What do we mean by integration?
Parsing and analyzing Binary files can be a headache when building binary tools like llvm-readobj because each target architecture has its own unique intricacies in its binary files even when they use standard file formats such as ELF.
Rust binaries make it worse/better by introducing new memory layouts, new symbol-mangling techniques, additional debugging symbols and additional linking symbols just to name a few parsing headaches. (I named a few because my knnowledge ends there, Help! 😂).
So in short, the resultant rust-made elf files are not really standard elf files, they contain additional rust-specific info. Normal Elf tools like llvm-readobj have the ability to parse these rust-made files, but they miss out on the rust-specific analysis.
For this reason, the Rust community provides modded versions of the LLVM-tools in form of a toolchain componet called llvm-tools-preview. This component contains a bunch of modded llvm-tools that can completely parse and inspect both normal and rust-made elf files.
The word "preview" in the name "llvm-tools-preview" is important because it indicates that the component is currently not stable and is under active development. You can view the development progress through this tracking issue.
You can add the llvm-tools-preview components to your Nightly toolchain by running this command :
rustup component add llvm-tools-preview
Cargo integration
To avoid leaving your cargo environment when programming, you can integrate llvm-tools-preview with cargo by running the following command :
cargo install cargo-binutils
That's it! Now you can churn out commands like these:
cargo readobj --all
cargo objdump --bin hello-world -- -d
cargo objdump --bin hello-world -- --segment
# ... read the cargo-binutils doc ...
This page has over-simplified things. Binary file inspection is a fundamental skill that is best learnt with practice and deep reading.
There is this book called : Binary Analysis for Beginners, build your own linux tools by David Andriesse. It may not be cutting-edge but it gets you acquainted with the fundamentals in a practical manner.
The UART
This book is about building a UART driver. So of course we have to have chapter that explains :
- what the UART is
- How the UART works
- Its uses
- Protocols involved
- UART registers
- insert many other buzz-sentences here
This chapter covers the theory about the UART itself.
Before we build a driver for any piece of hardware, we have to understand that piece of hardware first.
So here goes...
General Overview
What is the UART?
Before tackling the meaning of UART, let's get some acronyms out of the way.
- UART stands for
Universal Asynchronous Receiver/Transmitter. - Tx stands for
Transmitter. - Rx stands for
Receiver.
We're done with the acronymns, now we are on the same jargon wavelength.
The UART is an integrated circuit that takes in parallel data from one end and outputs serial data on the other end. It also receives serial data from one end and outputs parallel data on the other end.
So you can say that it is a parallel-to-serial converter with a few extra steps.
If you connect two UARTs as seen below, you achieve serial communication between two devices that have parallel data buses.
What does asynchronous mean in this case?
"Asynchronous" refers to the method by which data is transmitted and received between two independent devices without requiring a shared clock signal between the transmitting and receiving devices.
Instead of using a clock to synchronize the rate at which bits are exchanged, the two communicating devices agree on the data-packet format and the rate of transmitting the bits of that data-packet.
The rate at which the bits of the data-packet are transmitted is referred to as baud rate in this context.
So is UART a serial-communication protocol?
Well... The UART is not a communication protocol itself but rather a hardware component or module that facilitates serial communication between devices. You could say that it is circuitry that serves as the underlying hardware mechanism for implementing various communication protocols such as RS-232, RS-485, MIDI, and others
Confusing... right? ha ha.
UART == circuit.
UART != protocol.
You can implement various asynchronous protocols on top of the UART circuitry.
How the UARTs work.
In UART communication, two UARTs communicate directly with each other. The transmitting UART converts parallel data from a controlling device like a CPU into serial form, transmits it in serial to the receiving UART, which then converts the serial data back into parallel data for the receiving device.
Only two wires are needed to transmit data between two UARTs. Data flows from the Tx pin of the transmitting UART to the Rx pin of the receiving UART:
UARTs transmit data asynchronously, which means there is no clock signal to synchronize the output of bits from the transmitting UART to the sampling of bits by the receiving UART. Instead of a clock signal, the transmitting UART adds start and stop bits to the data packet being transferred. These bits define the beginning and end of the data packet so the receiving UART knows when to start reading the bits.
When the receiving UART detects a start bit, it starts to read the incoming bits at a specific frequency known as the baud rate (bits per second). Both UARTs must operate at about the same baud rate. The baud rate between the transmitting and receiving UARTs can only differ by about 10% before the timing of bits gets too far off.
So before any data transfer actually happens, the two UARTs must agree on :
- The Data packet format
- The Baud rate (bps)
Example Case :
From the above diagram, UART1, the UART that is going to transmit data receives the data from a data bus. The data bus is used to send data to the UART by another device like a CPU, memory, or microcontroller. Data is transferred from the data bus to the transmitting UART in parallel form.
After the transmitting UART gets the parallel data from the data bus, it adds a start bit, a parity bit, and a stop bit, creating the data packet.
Next, the data packet is output serially, bit by bit at the Tx pin. The receiving UART reads the data packet bit by bit at its Rx pin. The receiving UART then converts the data back into parallel form and removes the start bit, parity bit, and stop bits. Finally, the receiving UART transfers the data packet in parallel to the data bus on the receiving end.
If the communication between the two is asynchronous, how do they agree with each other in the first place?
-
Manual Configuration: In many systems, the baud rate is manually configured by the user or system designer. This involves setting the baud rate to a specific value (e.g., 9600 bps, 115200 bps) on both the transmitting and receiving UARTs. The configuration is typically done through software or hardware settings.
-
Default Baud Rate: In some cases, UART devices may have default baud rate settings. If both devices are configured to use the same default baud rate, no additional configuration is necessary.
-
Negotiation: In more advanced systems, UART devices may support auto-baud detection or negotiation protocols. Auto-baud detection allows a UART receiver to automatically determine the baud rate of incoming data by analyzing the timing of the start bits. This can be useful when the baud rate is not known in advance or may vary.
-
Hardware Handshaking: In certain situations, UART communication may also involve hardware handshaking signals (such as RTS/CTS - Request to Send/Clear to Send) to coordinate communication between devices. These signals can help ensure that data is only transmitted when the receiving device is ready to receive it, reducing the risk of data loss or corruption.
The UART data packet
The format of the data packet needs to be agreed upon by the two communicating UART circuits as earlier mentioned.
The format is typically structured as follows....
- Start Bit: The start bit signals the beginning of the data byte. It is always set to a low voltage level (logic 0). The duration of the start bit is one bit duration, determined by the baud rate.
The UART data transmission line is normally held at a high voltage level when it’s not transmitting data. To start the transfer of data, the transmitting UART pulls the transmission line from high to low for one clock cycle. When the receiving UART detects the high to low voltage transition, it begins reading the bits in the data frame at the frequency of the baud rate.
- Data Bits: These are the actual bits representing the data being transmitted.
The number of data bits can vary, but common configurations include 7 or 8 bits per data byte. It can be 5 bits up to 8 bits long if a parity bit is used. If no parity bit is used, the data frame can be 9 bits long.
The data bits are typically transmitted LSB (Least Significant Bit) first. The duration of each data bit is determined by the baud rate.
- Parity Bit (Optional): The parity bit, if used, is an additional bit for error detection. It can be set to even parity, odd parity, mark parity, space parity, or no parity (none).
Parity describes the evenness or oddness of a number. The parity bit is a way for the receiving UART to tell if any data has changed during transmission. Bits can be changed by electromagnetic radiation, mismatched baud rates, or long distance data transfers. After the receiving UART reads the data frame, it counts the number of bits with a value of 1 and checks if the total is an even or odd number. If the parity bit is a 0 (even parity), the 1 bits in the data frame should total to an even number. If the parity bit is a 1 (odd parity), the 1 bits in the data frame should total to an odd number. When the parity bit matches the data, the UART knows that the transmission was free of errors. But if the parity bit is a 0, and the total is odd; or the parity bit is a 1, and the total is even, the UART knows that bits in the data frame have changed.
- Stop Bit(s): The stop bit(s) signal the end of the data byte. Typically, one or two stop bits are used. The stop bit(s) are set to a high voltage level (logic 1). The duration of each stop bit is determined by the baud rate.
Advantages of using UARTs
- Simple, Only uses two wires
- Simple, No clock signal is necessary.
- Has a parity bit to allow for error checking
- It can accomodate custom communication protocols; The structure of the data packet can be changed as long as both sides are set up for it
- Well documented and widely used method
Disadvantages of using UARTs
- The size of the data frame is limited to a maximum of 9 bits.In scenarios where larger data sizes need to be transmitted, the limitation to 9 bits per frame can result in inefficiencies. It may require breaking down larger data sets into multiple frames, which can increase overhead and decrease overall efficiency.
- Doesn’t support multiple slave or multiple master systems
- The baud rates of each UART must be within 10% of each other
Clarifications
As seen from the image at the top of the page, the connection uses two wires to transmit data between devices. But in practice, you may use 3 wires for each device. For example, the 3 wires attached to UART 1 will be :
- The Transmitter wire (Tx wire) from UART 1 to UART 2
- The Receiver wire (RX) from UART 2 to UART 1
- The Ground wire
credits and references
- Credits go to this circuitbasics blog, for the images and elaborate content. You can give it a read.
- If you want to learn about the different serial communication protocols associated with the UART, this Raveon technical brief provides a short overview
UART Registers
There are many UART designs and implementations each with different tweaks. So we will stick to the NS16550a UART because it is the one that the Qemu-riscv-virt machine emulates.
NS16550a UART is also kinda generic. It is an old design, but very simple. It gets the job done without clutter.
The NS16550a also has two 16-byte FIFO buffers for input and output
If you want to check out the other different designs and implementations, go through this table.
References and Docs
Here are a few guiding docs that will help you learn more about the UART registers and configs.
- A blog-like explanation by Lammert Bies (start with this, it explains the most important bits without the electrical-engineering jargon)
- The 16550A datasheet (use this as a reference. It comes with electrical-references that wil come in handy if you are writing a driver for a physical UART)
UART Registers
The UART circuit gets manipulated through a set of registers.
This chapter is meant to describe each of those registers.
You do not have to memorize each register, just know that they exist. This chapter is best used as a reference-chapter instead of a prose-chapter.
The UART has 12 virtual registers built on top of 8 physical registers. This might sound confusing but it actually makes sense. This is because a physical register can be used differently under different contexts. For example, the first Register can be used as a logical write-buffer register when the user is writing to the UART, but when the UART is reading from the same register, it will be treated as a logical read-buffer register.
Below is a diagramatic representation of the 12 UART registers :
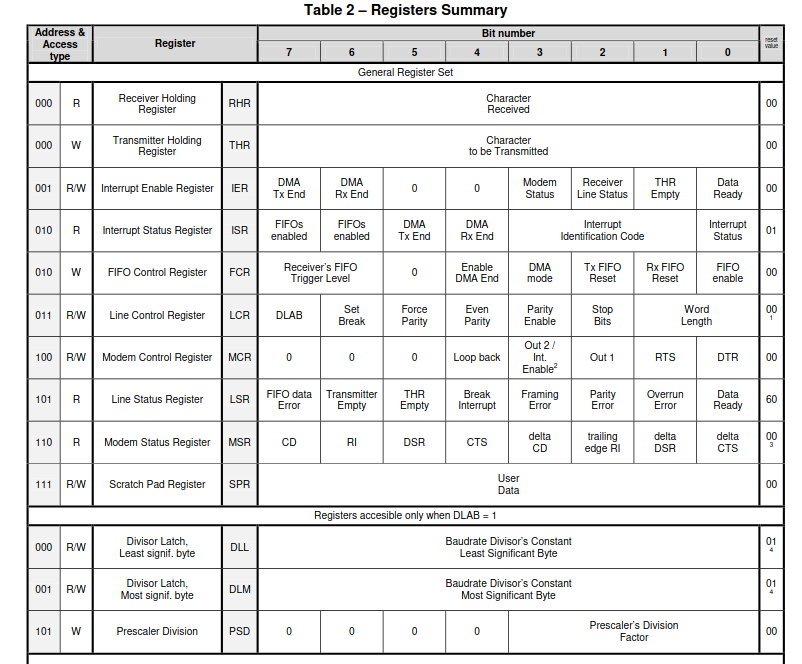
Notice that there are registers that share the same physical space. For example.... see below
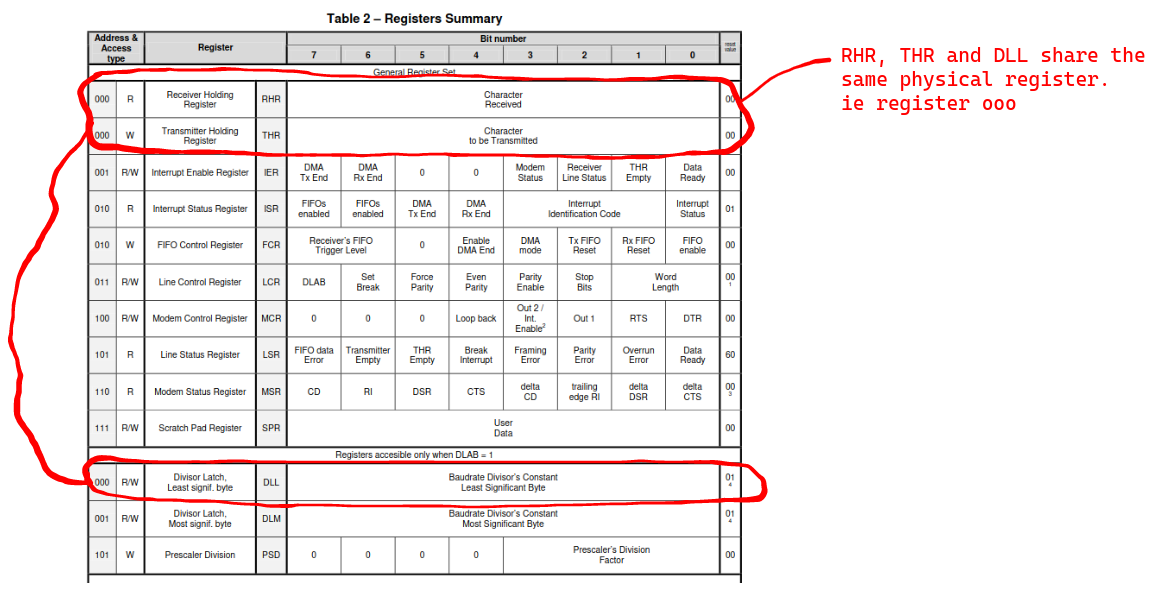
To understand the functionalities of each register, it's better to first understand the operations that they all try to achieve in unison.
So here are the operations that all registers try to achieve as a whole...
- Setting the Baud rate during configuration
- Modem control
- FIFO ontrol
- Interrupt handling
1. Setting the baud-rate
The baud_rate is the rate at which bits are received or transmitted. It is measured in Bits per second (bps).
The baud_rate needs to be set before data starts being set.
The maximum_baud_rate is the maximum rate at which bits can be sent or received. If we transmitted data at maximum baud rate, there is a high chance that buffer-overuns would occur.
The actual baud rate is less than the maximum baud rate. The actual baud rate is found by dividing the maximum baud-rate by a number of your choosing. ie.
# The NS16550a was designed such that each bit transmitted was given a duty-cycle of 16 clock ticks.
# The `clock_frequency` is the measure of 'how many ticks happen per unit time'. So the clock_frequency can be measured as 'ticks per second'. From here on, we will assume that the clock_frequency is measured as `ticks per second`
# To calculate how many UART_bits can be transmitted per second under a certain clock frequency, we do...
maximum_achievable_baud_rate = (Clock_frequency / 16)
# To avoid buffer overruns, we avoid using the maximum_baud_rate and instead reduce its value.
actual_baud_rate = (maximum_achievable_baud_rate / any_chosen_number) # The division here is just so that we can get a lower value than the maximum baud rate
any_chosen_number = (value_found_in_divisor_register) * (value_found_in_prescaler_register)
It is up to the driver programmer to specify code that will help in settig the baud_rate.
2. FIFO control
It is up to the driver programmer to provide a way to :
- enable and disable FIFO buffer usage
- Read and Write to the FIFO buffers in an error-free way
This passage has been borrowed from the data-sheet :
"The holding registers of both the transmitter (THR) and the receiver (RHR) can be formed by a unique 1-word register or by a 16-word First-In-First-Out (FIFO) buffer. At synthesis time the designer can select whether to implement or not the FIFOs (both at the same time, it is not possible to have a FIFO in one direction and a simple register in the opposite direction). If they are implemented, by software they can be enabled or disabled. When the FIFOs are disabled, the behavior is the same as if they had not been implemented. The UART working without FIFOs is what is commonly called the 16450 mode, due to the name of the industry standard UART without FIFOs. The FIFOs are enabled or disabled using the Fifo Control Register (FCR). It is possible to know if an UART has the FIFOs enabled by reading the Interrupt Status Register (ISR)."
3. Interrupt handling
The UART can generate an interrupt signal as the result of six prioritized interrupt sources. The sources, listed from highest to lowest priority levels, are:
- Level 1 (max.) - Receiver Line Status
- Level 2
- Received Data Ready
- Reception Timeout
- Level 3- Transmitter Holding Reg. Empty
- Level 4- Modem Status
- Level 5- DMA Reception End of Transfer
- Level 6 (min.) - DMA Transmission End of Trans.
The interrupt sources can be disabled or enabled via the Interrupt Enable Register (IER), which has one bit per each of the above six interrupt classes. Besides the IER, in order to make the irq pin active it may be necessary to set a global interrupt enable bit located in the MCR resgister (bit 3).
Once an interrupt is flagged, the CPU handles it and after handling it, the CPU should acknowledge that it has finished handling it. The CPU acknowledges the fix by changing the (undone) register.
The interrupt status of the UART can be read in the Interrupt Status Register (ISR). This register always provides the code of the highest priority pending interrupt
4. Modem control
We will not cover the modem-driver implementation. So you can skip to the next page if you want to.
This section is here for the sake of completeness. The 16550A Uart had a modem module. Modern UARTs don't typically have a modem module.
A modem is a device that is able to convert analog-signals to digital-signals... and vice-versa. It is different from a simple analog-to-digital converter because it has added functionalities such as compression, error-correction and adherance to certain communication protocols like the RS-232(Recommended Standard 232) and RS-485 standards.
So you could say that a modem is a fancy & heavily-moded analog-to-digital convertor.
The modem and the UART typically get used together... the modem can be used when the UART needs to send/receive analog signals.
So it made sense to add some bonus circuitry in the UART to communicate with modems. This modem-control circuitry is independent of the UART.
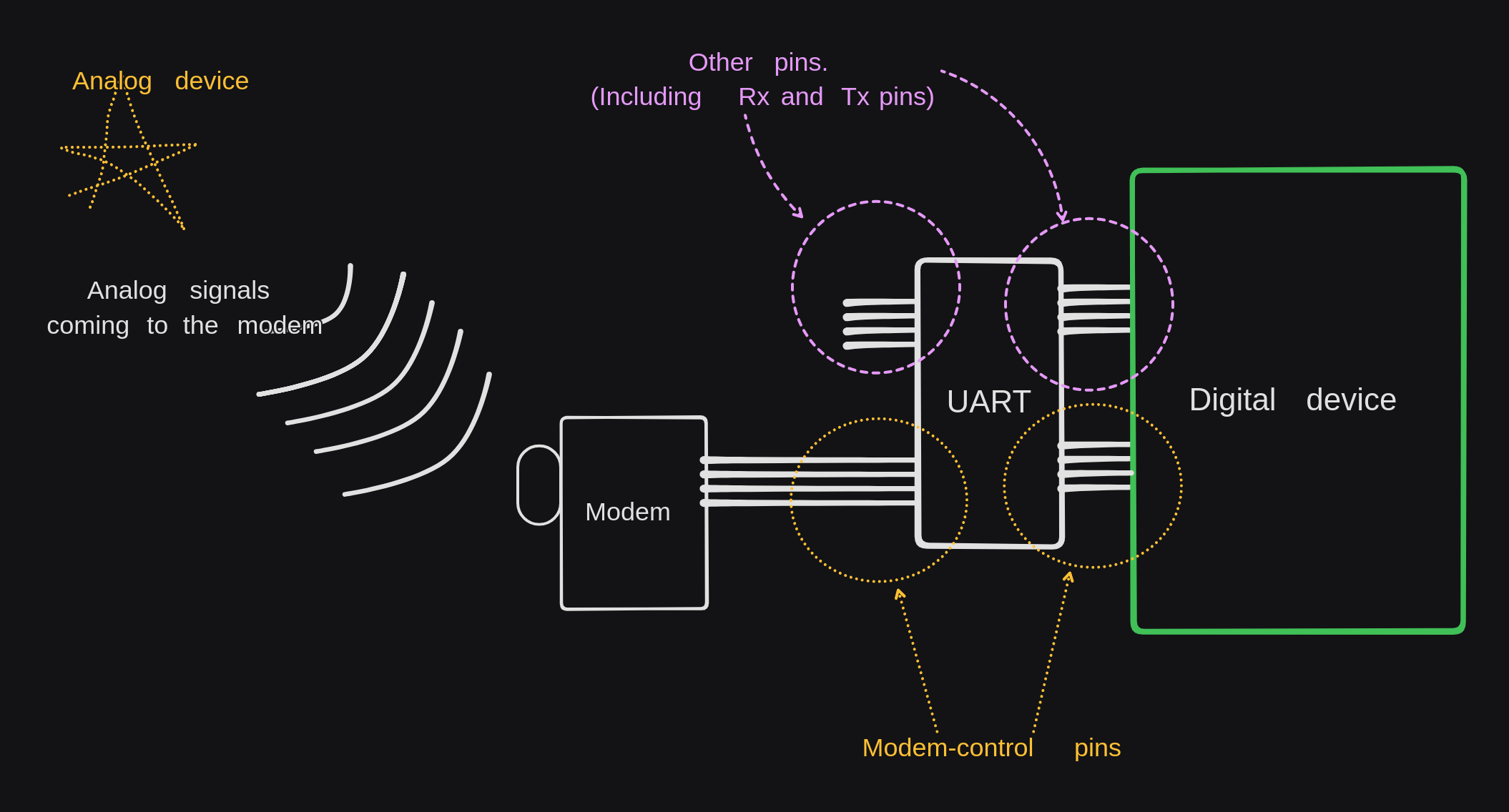
Modems use a variety of signals to establish, maintain, and terminate connections. We have Handshaking signals, modulation negotiation signals, flow-control signals and connection-termination signals.
It is up to the driver programmer to provide code that helps interacting with the modem-pins and registers found in the UART, this code will help in establishing, maintaining, and terminating modem connections. This driver-development bit is optional because the modem circuitry is not related to the functionality of the UART; it is just an added bonus.
Below are some explanations about the different signals that one needs to be aware of when dealing with modems.
A. Handshaking signals
When 2 modems want to communicate, they must first make sure that every-device is ready to either receive or send data. They do this by exchanging the following handshake signals.
-
Data Terminal Ready Signal: The sender sends this signal to the receiver to notify them that the sender is ready to communicate. The name of this signal is off because it has historical value and it has no modern meaning. In the context of early computing, a "terminal" referred to a device (typically a keyboard and a monitor) that allowed a user to interact with a mainframe computer. These terminals were essentially the user's interface to the computer system; the terminal acted as a client that sends signals to the mainframe and the mainframe responded just like a server. So the name
Data Terminal Ready Signalmeans "Sender/Cient is ready to communicate" -
Data Set Ready Signal: This is the signal from the receiver to the sender that confirms that it is ready to communicate with the sender who had earlier sent the Data terminal ready signal. In the past, the term "data set" referred to "the infrastructure being talked to by the terminal". So you could say that the term "data set" is a fancy word for "remote device"
-
Request to Send signal: After the sender(ie Data terminal) has received the
Data-set-Readysignal from the receiver, it sends out the Request to Send signal to the receiver. -
Clear to send signal: Sent by the receiver to indicate that it's ready to receive data.
Here are other less common signals (obsolete):
- Ring Indicator Signal: This signal is sent by the sender to the receiver to indicate that it wants to communicate. It is similar to a telephone ring. If the receiver receives this signal it switches from being in an idle state to constantly listening for the handshake signals or data.
- Carrier Detect Signal: This signal indicates that a physical connection has been established between the two modems and that valid data transfer is ongoing
B. Modulation and Demodulation:
Once handshaking is complete, the modems negotiate the modulation technique to be used for data transmission.
Common modulation techniques include Frequency Shift Keying (FSK) and Phase Shift Keying (PSK).
The sending modem modulates the digital data into analog signals for transmission over the phone line, while the receiving modem demodulates the analog signals back into digital data.
C. Flow Control:
Flow control signals ensure that data is transferred at a rate that both modems can handle. This prevents data loss that may occur because of buffer overflows.
Flow control can be achieved using hardware flow control (using RTS/CTS signals) or software flow control (using XON/XOFF characters).
Here are the pins that you can interact with when dealing with modem-UART-CPU communications.
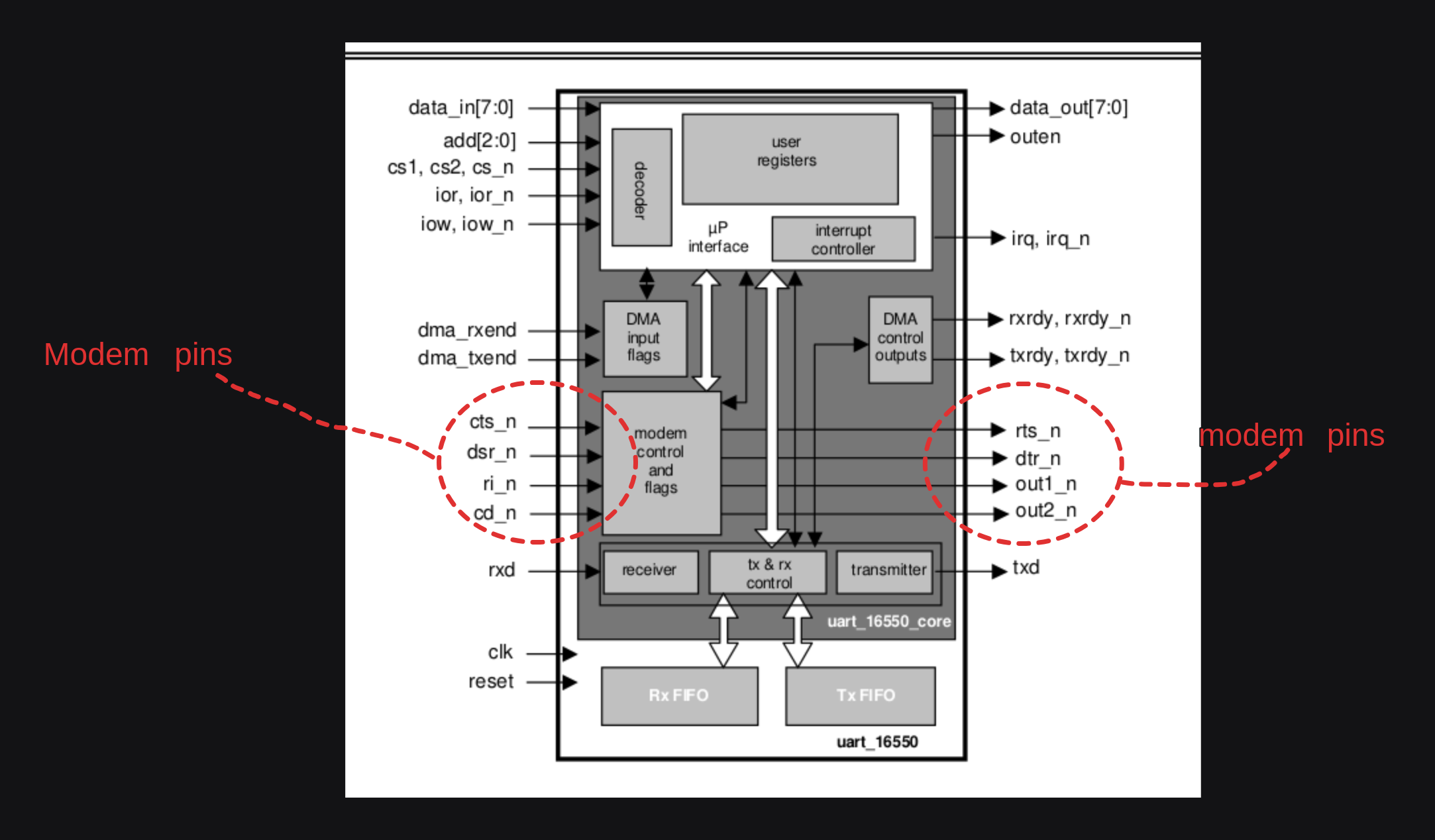
UART Registers- part 2
This page is unnecessary if you can read the 16550A datasheet on your own.
This page tries to highlight some points extracted from that datasheet.
Here we go...
Devices are connected via a physical layer. That physical layer has higher level protocols that can be implemented above it.
These higher level protocols outline things like :
- the way data gets packaged as signals (data-frame format).
- the speed at which bits should be transfered.
- the maximum distance allowed between the connected devices.
- the limit on the number of connected devices per physical connection.
- the decoding/encoding procedure & mechanism.
- the Pin layout of the physical interface.
- error handling (eg parity-checking)
- .... (so much more! If these things sound new... then you should read a communication book after this. Be a ham-radio hippie!)
The UART is a hardware component used for serial communication, and it can be used in conjunction with transceivers to interface with various physical-layer protocols like RS-232, RS-422, and RS-485.
There are many standards for creating a UART. The one that will be discussed here will be the 16550 standard which has the following distinctive characteristics.
- Has the ability to convert data from serial to parallel, and from parallel to serial, using shift registers.
- Has a multi-byte buffer for received data.
- Has another independent buffer for data that is yet to be transmitted.
- Has an interface that can interact with a DMA controller (interrupt-handling included).
- Has an interface that can interact with the microprocessor (interrupt handling included).
- Has Handshake lines for control of an external modem, controllable by software.
Component tree
- UART_16550A
- UART core
- microprocessor interface
- input decoder
- interrupt controller
- user/uart registers
- modem interface
- input decoder
- modem controller
- DMA interface
- input decoder
- DMA input controller
- DMA output controller
- rx/tx module
- receiver
- transmitter
- rx/tx controller
- microprocessor interface
- FIFO buffers
- Tx Buffer
- Rx Buffer
- UART core
The 31 pins in the UART design
The pins we are going to reference are from the schematic below:
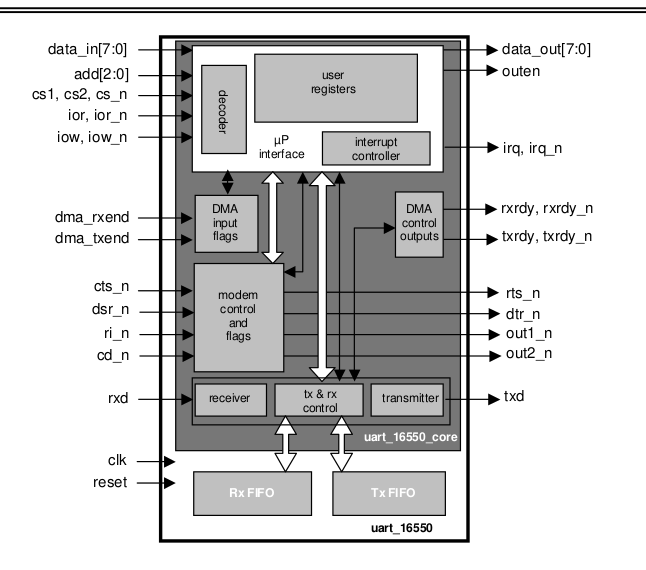
As seen in the diagram, the signals/pins have been grouped into:
- System signals
- Microprocessor data interface
- Interrupt signals
- DMA interface
- Modem interace
There are places where there are redundant pins. For example ior and ior_n. This redundancy ensures :
- compatibility of the UART module across different boards
- flexibility to accomodate different signalling processes
- good old redundancy
1. The clock pin
The clock pin signal comes as an input to the UART module. During the rising-edge of the signal, all registers in the UART module moves.
2. The Reset pin
A high signal via the Reset pin triggers a System reset: Every register resets asynchronously to a predefined state.
add[2:0]
Uart-Register-index to read/write to.
Chip-select pins
Many peripherals share the bus that connects them to other resources like memory and processor.
To avoid conflicts, the connected peripherals only interact with the bus after they receive a chip-select signal from the processor.
The UART module has both active-high and active-low chip-select pins for the sake of compatibility with boards ie. you do not have to change the active-level of your signal because the UART wants you to deliver active-high only.
The UART module has 2 active-high chip-select pins for the sake of flexibility and redundancy.
Flexibility:
- you can connect the chip to 2 different buses
- Some systems may require one chip-select pin to interact with the address bus, while the other might be connected to a control line or system management unit. Having two chip-select pins ensures that the UART can be integrated into a wider variety of microprocessor or microcontroller systems, offering more design options
Redundancy:
- you can configure the UART such that chip-select becomes true if all 3 CS-pins attain a certain combination thereby reducing 'false positives'. This is better than relying on input from only one source.
In our case, for any read or write operation to happen, cs1, cs2 and Cs_n must be set to HIGH, HIGH, LOW.
IOr and IOr_n
This pins carry the read_strobe/read_signal. The processor sends the read strobe signal to the UART so that the UART can get prepared to be read from. This step looks unnecessary, but it gives the UART a heads up that it should get things in order before the read so that we avoid reading garbage. (it should rearrange the buffer if necessary, parity-check data in the data-received register and be ready to acquire access to the data-bus)
In our case, A read operation is executed when the chip select condition is met and the signal ior is 1 while ior_n is 0.
IOw and IOw_n
Just like IOr but for a write operation instead of a read operation.
A write operation is executed when the chip select condition is met and the signal ior is 1 while ior_n is 0.
data_in[7:0]
input data to be written to a UART register specified by the index supplied by the addr[2:0] pin
data_out[7:0]
output data to be read from a UART register specified by the index supplied by the addr[2:0] pin
outen
When High, it indicates that a valid register-read operation is ongoing in the current clock cycle. This info is releant to external devices such as an overall connetion-manager that has intermixed multiple UARTs. This pin can just be left unconnected if you have no use for it.
Interrupt signals (irq and irq_n)
If the uart wants to send an interrupt to the microprocessor, this output pin is toggled HIGH until the interrupt condition is removed using the UART driver. To reset the condition, the processor has to perform appropriate reads or writes to the UART. This is executed by the UART
driver.
DMA signals (rxrdy and rxrdy_n)
When the UART wants to send data to memory via the DMA, it sends a rxsdy signal to the DMA controller.
DMA signals (txrdy and txrdy_n)
When the UART wants to read data from memory via DMA, it sends a txrdy signal to the DMA controller.
DMA signals (dma_rxend and dma_txend)
After the DMA-controller affirms that the read/write operation is complete, it sends dma_txend/dma_rxend to the UART as an interrupt and flag.
Modem signals.
The modem signals are indentical to the modem-handshake signals. The signals abstract the UART as the sender(Data terminal) and the remote modm as the receiver(Data Set)
- cts_n : Clear To Send. Used to provide flags and an interrupt.
- dsr_n : Data Set Ready. Used to provide flags and an interrupt.
- ri_n : Ring Indicator. Used to provide flags and an interrupt.
- cd_n : Carrier Detect. Used to provide flags and an interrupt.
- rts_n : Request To Send. Controlled by a register’s bit.
- dtr_n : Data Terminal Ready. Controlled by a register’s bit.
There is no relation between the modem control block and the serial transmission/reception blocks
Serial Communication signals (rxd and txd)
-
txd : Serial output signal. This is the pin that is used to transmit the data bits from the UART to another remote receiver. When the UART is not communicting (ie idle) this signal hangs at a HIGH.
-
rxd : Serial input Signal. This is the signal that comes with received data coming from a remote UART. If there is no communication between the two UARTs, this signals hangs at a HIGH.
The UART implements for the rxd input an anti-metastability filter followed by a majority filter.
This inserts a delay of three clock cycles in the view of the rxd that the receiver has respect to a direct sampling of rxd.
General Purpose Outputs
There are two general purpose 1-bit output pins whose output values can be controlled by software (driver/firmware)
These pins' value correspond to the state of a couple of bits in the Modem Control Register.
Since one of these two bits can implement a standard global interrupt enable bit (depending on a synthesis option), the out2_n may
be not so “general-purpose”.
Operations using the above signals
Data serialization
Using software, the driver will set bits in the line control register to determine the format of transmitted bits.
The format of bits sent is as follows:
- the first bit is a low signal that drops the idle state of the tx-line or the rx-line. This is the start bit.
- the bits that immediately follow are data-bits representing the actual message. They are collectively called a
word. It is up to the driver to choose the word-length. It can be 5,6,7 or 8. - an optional parity bit follows
- and finally, one or more stop bits follow. The stop bits are all LOWS (ie zeroes). The receiver only checks the first stop bit, with independence of the number of stop bits programmed.
Data Transmission
With the help of the uart-driver, the microprocessor writes data(the word) to the Transmission Holding register. This data is pure data...it doesn't contain the start, parity or stop-bits. It fits the word-length configured in the Line control register.
From there, the data is transferred to the Transmission Shift register starting with the least significant bit. This is where the serialization happens before transmission ; a start, stop and an optional parity bits are added.
Data flows out through the tx output pin
The DMA does not directly push its data to the Transmission holding register. The DMA pushes to the Transmission FIFO buffer
Data Reception
The first point of contact is the anti-metastability filter followed by a majority filter. The anti-metastability filter introduces a 2-cycle delay for each bit-signal. The majority filter samples the bit with the assumption that the bit-cycle can be abstracted into 16-parts. This is why the maximum baud-rate is the max-clock-frequency divided by 16. (each bit == 16 clock cycles)
The majority filter then transfers each averaged bit into the Receiver Shift register that converts the word into a parallel format. After full word-assembly, it transfers the data into the Receiver Holding Register where it is read from by the micro-processor.
The errors that can occur during data reception are:
- Parity Error: Occurs when the parity bit does not reflect the actual parity of the received data.
- Overrun Error : this happens when the receiver receives a new word before the microprocessor reads the previously acquired word. This may results in a data loss if no additional circuitry is provided (eg circuitry that pastes the new word in an emergency buffer)
- Framing Error: Happens when the stop-bit is a HIGH instead of a low.
- Break Interrupt: The break between interrupt should not be longer than a word-cycle. ie the stopbits should not run for an entire word-cycle. The Break interrupt error is thrown when stop-bits span an entire word-cycle
Baud rate setting
As earlier stated, the maximum baud-rate is the rate at which the 16-cycle-uart-bits are transmitted ie max_baud_rate = clock_frequency / 16
To avoid overrun errors, we use a baud rate that is lower than maximum baud rate. Also, if we get two uarts with differing clock frequencies, we choose to go with the one that has a slower process capability.
To reduce the baud rate we use the following formulas.
max_baud_rate = clock_frequency / 16
baud_rate = maximum_baud_rate / { (Divisor_latch_register_value) * (Pre-scaler-division-register-value + 1)}
setting the Pre-scaler-division-register is optional.
Interrupt handling operations
The interrupt controller sends out interrupt signals to the microprocessor after checking out the following interrupt-info sources (arranged in accordance to priority):
- level 1. Interrupt status register
- level 2. __
- Received Data Ready
- Reception Timeout
- level 3. Transmitter holding reg.Empty
- level 4. Modem Status
- level 5. DMA Reception End of Transfer
- level 6. DMA Transmission End of Trans.
You can enable/disable the above six interrupt classes using the Interrupt enable register. It has bit spaces for each level of interrupt source.
Interrupt-worthy events trigger a change in the values of the Interrupt-status-register. The irq pin will always be on a high unless the interrupt status register contains no & enabled interrupt-worthy values.
So to inform the UART that the micro-processor had dealt with an interrupt, you have to use the uart-driver to change the values of the interrupt-status-register.
To help the driver in handling interrupts, the interrupt-status-register also provides the code of the current highest priority interrupt.
Receiver line Status interrupts.
These are interrupts that occur when the there's an error in receiving data. ie FramingError, ParityError and Break interrupt.
If these errors are detected, the corresponding bits in the Line-Status-Register are set to High. The irq output pin also gets set High.
Received Data Ready interrupts
This is an interrupt that gets sent under the following 2 conditions:
- If the UART is operating in 16450 mode and there is data in the Register-Holding-Register. To document this interrupt, the corresponding bit in the Line-status-register and the
irqoutput get toggled to a High. Both values will be toggled to low once the micro-processor reads from the RHR. - If the UART is operating in 16550 mode and the FIFO register has reached the limit of words set at the FIFO-Control-Register. To document this interrupt, the corresponding bit in the Line-status-register and the
irqoutput get toggled to a High. Both values will be toggled to low once the micro-processor reads from the FIFO to a point that the number of buffered words go below the threshold set at the FCR.
Reception Timeout interrupt
In FIFO-mode a timeout interrupt is implemented independent of the FIFO threshold.
This timeout interrupt is triggered if the UART is no longer receiving new data AND the FIFO has not reached its word-threshold.
The timeout period is equal to 4 word-cycles. (The word-length used in the timeout calculation should be inclusive of the actual data plus all the start, stop and parity bits)
The timeout interrupt is not reflected as a value in the UART registers such as the Interrupt status register.
Transmitter Holding Register Empty
In 16450 mode, this interrupt gets triggered when the Trnsmitter Holding Register becomes empty.
In 16550 mode, this interrupt is triggered when the FIFO buffer becomes empty.
If the interrupt happens, it gets documented in the corresponding bit in the Line status register.
Modem Status Interrupts
If enabled, an interrupt will be generated whenever a change is detected in the modem control input pins. For ri_n input the change must be from 0 to 1.
This interrupt is directly related to bits 0 to 3 of the Modem Status Register.
DMA interrupt signals
(undone)
DMA operations
The UART provides the following 6 pins for DMA-interactions
- (rxrdy and rxrdy_n) output signals from UART to DMA-controller, they inform the controller that there is data ready to be read.
- (txrdy and txrdy_n) output signals from UART to DMA-controller, they inform the controller that there the UART is ready to receive data through DMA.
- (rxrdy_end and txrdy_end) input signals to UART from DMA-controller to signify that a dma-data-transfer is complete.
How the above inputs change is based on the selected DMA mode.
There are 2 dma modes:
- DMA-mode 0
- DMA-mode 1
DMA-modes are selected by toggling bit 3 of the FIFO-control-register.
DMA-mode 0
This mode works in both 16450 and 16550 uart modes. It works in 16550 mode ONLY if the threshold of the receiver FIFO is zero.
If there is data in the RHR, the rxrdy output signal goes high.
If there is at most 1 word in the receiver-FIFO, the rxrdy output signal goes high.
The rxrdy signal goes low only when both the RHR and receiver-FIFO are empty.
The txrdy signal goes high only when both the THR and transmitter FIFO buffer are empty. txrdy goes low if there is atleast one byte in any transmision buffer. (ie, both THR and transmitter Buffer)
DMA-mode 1
This mode works only in 16550 mode.
The rxrdy signal goes High only when either of the following occur:
- The Receiver FIFO set-threshhold is hit or surpassed.
- The receiver timeout gets triggerd The rxrdy signal goes low only when the FIFO becomes empty again.
The signal txrdy goes from an active to an inactive state when the transmitter’s FIFO gets full. After this, it is kept inactive until the transmission FIFO gets empty.
Modem control
All the modem output values can be set in the modem_control register.
All the modem input values can be read in the modem_status register.
All these pins are active low. The modem registers employ a positive polarity, so a low in the pins will reflect as a high in the registers.
The MSR(Modem Status register) also provides flags to indicate a change in the status of the input pins. These flags can generate an interrupt to the microprocessor if desired.
FIFO buffers
The Uart can operate without the 16-byte buffers and instead depend only on the transmitter/Receiver holding register. This mode is usually referred as 16450 mode.
But you can enable the FIFO-buffers using the FIFO-control register. It is also possible to check if FIFO buffers have been enabled by reading from the Interrupt status register.
Being 8 bits the maximum data word length, the transmitter FIFO is 8-bits wide. However the receiver FIFO is by default 11-bits wide. This is due to the fact that the receiver does not only put the data in the FIFO, but also the error flags associated to each character. This last size can be reduced to 10-bits wide, without sensibly decreasing the compatibility, by using a synthesis options
Loop back implementation
We wont discuss this.
The scratchpad register.
We wont discuss this.
The UART registers
For some reason, I am just going to leave this here. I hope you can look at the image and connect the dots based on the discussions we've had before this...
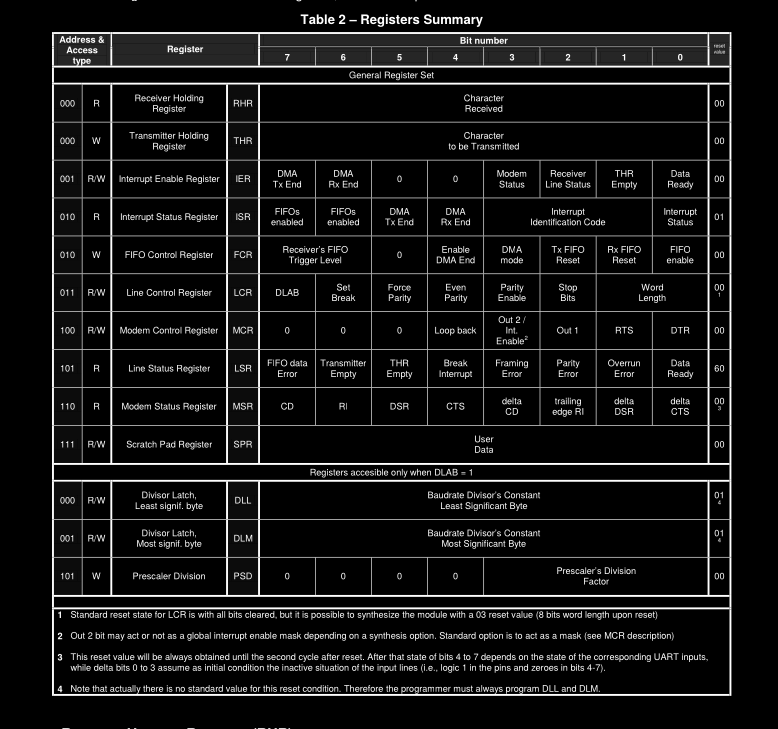
From here on, we abstract each register using code. So read up on a register from the datasheet and see how you can abstract it.
You can view the example abstractions at this module
- RHR register
- The RHR is read-only external conditions
- If you read from RHR, then the DLAB bit in LCR must be zero
- Before reading the RHR,
Abstractions
Now we have understood the registers of the UART device. It's time to build software above it.
You can read these 2 sources on abstraction layers above the hardware:
- Embedded Rust Book - Mapped Registers Chapter
- Embedded Rust Book - Portability Chapter
As we have done in other chapters in this book, I will just go on ahead and summarize the above docs in an inaccurate manner.
You can spot the lies everywhere in this text.
Roughly speaking, here are 5 Abstraction crates over Hardware arranged from most-low-level to most-high-level.
| Abstraction Layer Name | level |
|---|---|
| Microarchitecture crate | (level 1) |
| Peripheral Access Crate | (level 1) |
| Hardware Access Layer | (level 2) |
| Board Access Layer | (level 3) |
| Runtime Layers | (level 4) |
Here is a pic extracted from the Embedded Rust Book :
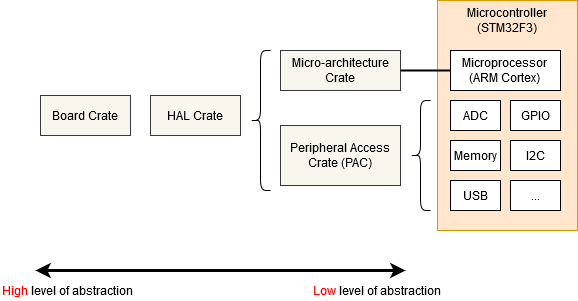
MicroArchitechture crates (MACs)
This crate abstracts away the processor Architecture itself. This crate is pretty constant across Processor families. It's API provides things like :
- rust-wrapped assembly commands
- provides a framework to manage interrupts (as prescribed by the processor)
- provides a way to abstract critical sections as implemented by the Architecture.
Examples of MAC crates include : cortex-m and riscv Go check them out, try to see what they abstract.
Peripheral Access Crates (PACs)
These crates abstract away the registers of the physical devices. (ie They abstract away peripherals). Eg the UART, I2C and USB modules.
In other words.. this kind of crate is a thin wrapper over the various memory-mapped registers defined for your particular part-number of micro-controller that you are using.
By convention, peripherals and the processor are considered to be separate units. However, some peripherals are sometimes considered to be a part of the micro-architecture(processor) eg the system-timer in cortex-m boards. As a result, the crate above the system-timer becomes part of the MAC instead of the PAC. The line between MACs and PACs is vague... you could say that the MAC is a PAC above the Micro-processor! And we are back to the naming problem in the software world.
Examples of PACs include: tm4c123x, stm32f30x
Hardware Access Layer
The hardware access layer is an API that tries to abstract away the combination of both PACs and MACs. It summarizes its API into a group of traits that represent functions generically found in most processors.
We will look at the embedded-hal in a future chapter (undone)
Board Access Layer
This board builds upon the Hardware Access Layer by configuring the API exposed by the HAL to suit a specific board. We will also look at this in a future chapter. (undone)
Runtime Layers
The Runtime layer is more of a hypervisor than a simple abstract crate. It manages things like concurrent use of the hardware below. It takes care of booting (or even safe booting), flashing-safety, logging, loading, debugging & updating of firmware, ...
To put it inaccurately, it is a small minimal kernel over your board. So really, in reality we cannot say what its definite functions are - it is up to the runtime library creator to figure that out.
Bottom up
We will try to build all these layers as we go. They will not be full implementations, but they will provide the framework to understand how full implementations get built.
Where is the harm in re-iventing the wheel?
Abstracting a Peripheral
Instead of writing paragraphs, let's just build peripheral drivers and hope to learn along the way.
We will build PACs above the following peripherals:
- The SystemTimer for a cortex-m board
- The SystemTimer for an ESP32 board
- The 16550A UART found in the Qemu board
- The UART found in the ESP32 board.
Why is the list long?
The list is long because we want to learn through practice, through lots of practice. If you are in a hurry, I suggest you just skip to the chapters that cover the PAC for the UART found in the ESP32 board.
Why those peripherals?
- The cortex-m timer is very basic. It has 4 registers only. For this reason, it was chosen as the first practice point.
- The ESP32 system timer is not as basic as the cortex-m timer, but it is less complex in comparison to the UART. For this reason, it was chosen as an intermediate step.
- A virtual UART gives us room to make mistakes
- I don't think we have to explain why the last peripheral was chosen.
Off we go....
System Timer - Part 1
The system timer described in the espc3 reference datasheet is more complex than the system timer in the ARM reference manual. For this reason, we will experiment with the ARM system timer before moving on to the espc3 system timer.
So what's the PAC-creation process like?
-
Read the concerned datasheet segment of the ARM reference manual (6 pages inclusive of diagrams). You need to understand the little details, you are a low-level programmer. Read the full specs or you'll fuck up a user somewhere in the world.
-
Outline all the registers concerned. Outline the fields within each register. List all the allowed values of each register field. This info will be useful to you when you'll be creating a state diagram of the state changes in the register values.
-
List all functionalities achievable by the peripheral. This list MUST be EXHAUSTIVE. This list will help you design a better state digram, a better API and exhaustive tests.
-
Create a functional state diagram for the entire peripheral.
-
Create a functional-test document. Just write the exhaustive tests( dont get hang up on trying to implement them, you just write them for future implementation.) Arrange them by priority level so that in case you dont implement all of them, you would have at-least implemented the essential tests.
-
Write your abstractions in accordance to the functional-state-diagram and then write your tests.
-
Refine your API in accordance to other common PACs
Step 1,2,3,4 and 5 are all about creating a System View Description. This is because they are focussed on describing the structure and functions of the hardware.
Describing peripherals and their memory mapped registers on paper is a messy affair, that's why developers came up with different standards/formats of writing such descriptions.
In this book, we will stick to the SVD format because of the existence of the svd2rust crate.
SVD files are usually provided by the microprocessor manufacturer. For example, the svd files for the esp32c3 can be found here
But before we use the svd files from the manufacturer, let's try to create our own descriptive files.( our own custom format that does not follow the SVD rules)
Non-SVD System Descriptions
The limitation of svd files is that...
- They do not programmatically describe functionalies of the different peripherals and their respective registers. SVD files describe the fuctionalities of the registers in the form of
<descriptions> bla bla bla <description/>which usually get treated like comments - they are not parsable. It would probably be better to have register-functions described programmaticaly (i.e in a way that can be easily parsed into code. This will encourage meta-programming and automatic testing just from the svd file) - They do not describe the timimg constraints of the register changes and their side-effects. eg
- "Reading from the DATA register might automatically clear a "Receive Data Ready" flag."
- "Writing to the UART1 DATA register might require waiting for a "Transmit Ready" flag in a status register"
- They do not describe the inter-dependence between the peripherals eg If you change register
xon deviceY, the registeraon deviceBwill get toggled automatically. Real example: Changing the system clock frequency (usually done through a Clock Control peripheral) might affect the baud rate settings of UART peripherals.
The above points make the svd format unsuitable for automatic generation of functionally-correct code. SVD is good at describing memory maps but it relies too much on the memory and understanding of the firmware/driver developer to constrain functionalities and timing details.
There are more thorough device description formats out there that describe more about the hardware than SVD files. For example:
- IP-XACT (IEEE 1685). You can find its user guide here.
- SystemRDL
- UVM RAL
- JSpec - a register description format used within Juniper Networks
Tooling is expected to work in :
- Header generation'
- Driver generation
- SystemRDL-ipxact-svd translation
- Auto-documentation
- Auto-testing
System Timer - Step 1 & 2
As earlier mentioned, the first 2 steps in creating a PAC are...
- Reading the concerned datasheet segment of the ARM reference manual and understanding it.
- Outlining all the registers concerned. Outlining the fields within each register. Listing all the allowed values of each register field.
I can't help you do step 1.
Here is how I did step 2:
Registers :
Registers and MMIO programming
You know your hardware by reading the relevant parts of your datasheet.
Your hardware is like a library, the datasheet is its documentation.
MMIO Programming
But before we talk about the datasheets, let't talk about MMIO-programming.
MMIO involves using memory addresses as an interface to communicate with and control hardware devices.
Memory-Mapped I/O refers to the technique of accessing hardware registers and controlling peripherals using memory addresses. Instead of specialized instructions, developers interact with hardware by reading from and writing to specific memory addresses, treating hardware like memory-mapped regions.
Hardware Registers: Peripherals and hardware components are often controlled by registers, each associated with a specific functionality (e.g., configuration, data transmission, status).
So to control hardware, you read and write to the respective registers... or memory regions.
The Volatile key word
Quick detour :
Facts :
- Your code does not always get executed procedurally.
- Some lines from your code get ignored or cut out by the compiler or CPU.
The compiler optimizes the order of instructions, it even makes assumptions : eg
#![allow(unused)] fn main() { let register_1 = 1; // insert other instructions here let register_1 = 1; }
can be optimized to
#![allow(unused)] fn main() { let register_1 = 1; // insert other instructions here // let register_1 = 1; // gets truncated }
The CPU also optimizes and changes the order of those instruction even further.
If you add parallelism to the matter... it just makes it impossible to be sure that your instructions get executed in a specific order.
These optimizations are bad if the changes to the register truly matter.
Enter the volatile key-word... the superhero
The volatile keyword makes reads and writes to be atomic and un-reordered(if that'ts a word).
It is the embodiement of :
"Hey, compiler and CPU, no optimizations should affect the order of my reads and writes. I cannot deal with surprises please"
useul when the order and timing of reads and writes are critical, and the compiler should not make any assumptions about the potential side effects of these operations.
example in rust :
// Import necessary modules use core::ptr; fn main() { // Define a mutable pointer to a memory-mapped address let mut mmio_ptr = 0x4000_0000 as *mut u32; unsafe { // Read from a volatile memory-mapped address let value = ptr::read_volatile(mmio_ptr); println!("Read value: {}", value); // Write to a volatile memory-mapped address let new_value = value + 1; ptr::write_volatile(mmio_ptr, new_value); println!("Written new value: {}", new_value); } }
Summary :
- You control hardware by reading and writing to its registers.
- All reads and writes to the registers have to be done using the volatile keyword.
Question : Why do you think Volatile reads and writes are not the default methods. why are unpredictable reads and writes the default methods?
Abstraction using strict provenance.
Many Rust developers use Rust because of its inbuilt memory safety.
Unsafe rust is not so safe. It tries hard, but it is named unsafe for a reason.
Strict Provenance is a concept on how to make it harder to mess up pointer manipulation in Rust, even in unsafe code blocks.
It is an unfinished project that you can check out in this thread.
The rust compiler currently does not observe strict provenance but tools like MIRI and CHERI do.
So running cargo miri run will catch more errors than the normal cargo run.
(needed contribution: anyone with info on cheri can contribute to this page)
We really hope this project grows.
This is a super-power loading.
Being that this is a new topic, the author will just list the docs they read and provide tips along the way.
Any developer with more experience is welcome to over-write all content concerning strict-provenance.
Direction
- Start here : initial draft by Aria Desires
- If you need some practice with pointers, read "Learn Rust by writing Entirely Too Many Linked Lists".
- Reas up on Stacked Borrows
- Continuously read up on the concepts brought up in the github thread
Knowing your Hardware
Your hardware is like a library, to use it correctly, you should know it well... or at least know the relevant parts.
To understand your hardware, you read the datasheet. Like this one : the esp32 datasheet
The 20% of the 100%, the important parts :
- Understand the functional features and capabilities
- Understand the hardware registers AND pins of the hardware you want to control.
What's the diference between pin and a register in mmio?
Figures
-
Physical board with Pins

-
Pin Layout
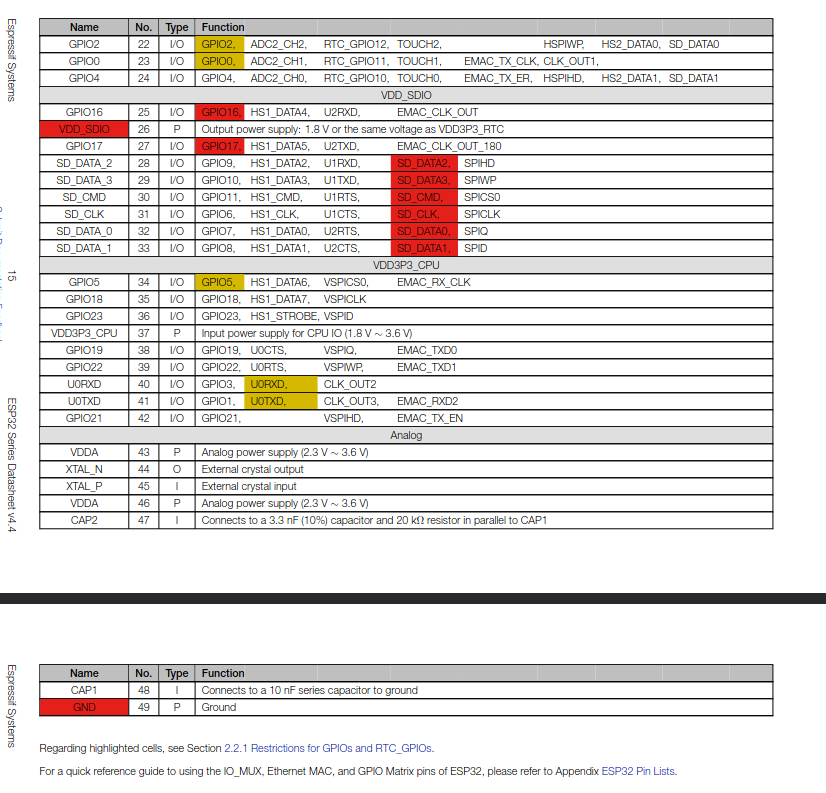
-
Memory Layout (Registers + Actual_memory)

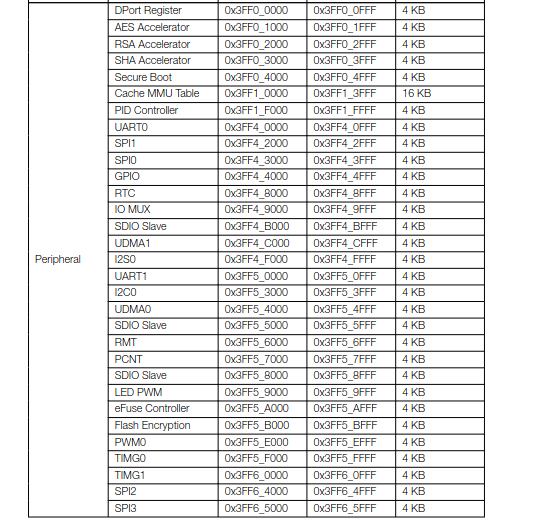

svd2rust
Once you read the datasheet and understand the memory mappings, pin-layout and whatever else you wanted to get straight, you may begin to safely abstract the board.
SVD files
An svd file is a file that describes the peripherals of a board using xml. So you could say that an svd file is a board abstracted as an xml template.
SVD is the abbreviation for : System View Description.
The svd file outlines :
- The boards metadata eg boardname, board version, feature description, vendor name
- Major component info : eg CPU_capabilities, Endianness, address_width, added cpu_extensions...
- all list of all the peripherals
- the registers of each peripheral
- the functions of each register
- the memory address of each register
- the read/write access of each register
You can find sample svd files [here][espressif_svd_file_samples], they are from the espressif organization.
Here is the esp32C3 svd file that we will be using : [ESP32_C3 svd file][esp32c3_svd_file]
Here is a snippet of a sample svd file :
<?xml version="1.0" encoding="UTF-8"?>
<device schemaVersion="1.1" xmlns:xs="http://www.w3.org/2001/XMLSchema-instance" xs:noNamespaceSchemaLocation="CMSIS-SVD_Schema_1_1.xsd">
<vendor>ESPRESSIF SYSTEMS (SHANGHAI) CO., LTD.</vendor>
<vendorID>ESPRESSIF</vendorID>
<name>ESP32-C3</name>
<series>ESP32 C-Series</series>
<version>17</version>
<description>32-bit RISC-V MCU & 2.4 GHz Wi-Fi & Bluetooth 5 (LE)</description>
<!-- snip snip snipped some lines -->
<cpu>
<name>RV32IMC</name>
<revision>r0p0</revision>
<endian>little</endian>
<mpuPresent>false</mpuPresent>
<fpuPresent>false</fpuPresent>
<nvicPrioBits>0</nvicPrioBits>
<vendorSystickConfig>false</vendorSystickConfig>
</cpu>
<!-- snip snip snipped some lines -->
<peripherals>
<!-- here is 1/32 peripherals -->
<peripheral>
<name>UART0</name>
<description>UART (Universal Asynchronous Receiver-Transmitter) Controller 0</description>
<groupName>UART</groupName>
<baseAddress>0x60000000</baseAddress>
<addressBlock>
<offset>0x0</offset>
<size>0x84</size>
<usage>registers</usage>
</addressBlock>
<interrupt>
<name>UART0</name>
<value>21</value>
</interrupt>
<registers>
<register>
<name>FIFO</name>
<description>FIFO data register</description>
<addressOffset>0x0</addressOffset>
<size>0x20</size>
<fields>
<field>
<name>RXFIFO_RD_BYTE</name>
<description>UART 0 accesses FIFO via this register.</description>
<bitOffset>0</bitOffset>
<bitWidth>8</bitWidth>
<access>read-write</access>
</field>
</fields>
</register>
<!-- more registers -->
<register>
</register>
</register>
<!-- more registers -->
<peripheral>
<!-- snipped out the other 31 peripherals -->
<peripherals>
svd2rust
svd2rust is a tool that takes in svd files and outputs Rust code that reflects the contents of the svd file. It automatically creates PACs over peripherals of a board.
Why use svd2rust instead of doing the abstraction manually?
Is this even a question?
Dear reader, love yourself. Love yourself. The world is so big and there is so much to do.
Whenever you find a tool that can convert +1000 pages worth of documentation into working code, do not hesitate to use that tool - then go ahead and build more abstractions.
You are free to read the docs of that tool and replicate what it does... you are free to learn from it by re-inventing its wheels, you can even improve its wheels... but please - Do not do the same EXACT work manually.
But anyway, let's answer the question... ignore whatever rubbish I just talked about.
When to abstract manually and ignore automation tools like svd2rust
- When you just want to learn and you want to go as low-level as possible and do things by your own intuition.
- When you fully understand all the details about a peripheral and you are confident that you'll make better abstractions than the automation tool
- When you fully understand all the direct components that the target peripheral depends on.
- When you can comfortably abstract the peripheral and its dependents, in a safe way: Automation tools like svd2rust easily integrate with critical section control across many boards.
- When you just want to have fun.
When to do it automatically
- When you mind abstracting all the dozens of peripherals by hand (2000+ lines of pure xml)
- When you want a library to automatically implement the access-safety methods of accessing registers. You don't have to implement atomic vodoo on your own.
- When you want to use a standard way of abstracting the board for the sake of source-code portability. If your whole team uses the same abstraction template, then everyone will feel like they are speaking the same language and everyone will be happy. The world would then become this peaceful place where there are no wars and people try to understand each other before nuking each other.
- When you take no pride or fun in writing boiler-plate code.
Assignment
Reader, go read the svd2rust docs and experiment with it.
Come back after you are done!
Bye.
For those who just want a summary, here is a watered down look into the svd2rust crate. Cheatsheet
SVD
alternative :
device:
name: ACME1234
architecture: ARM Cortex-M4
clock:
main_oscillator: 16MHz
pll:
input: main_oscillator
multiplier: 6
divider: 2
peripherals:
- name: UART1
base_address: 0x40001000
interrupts:
- name: UART1_RX
number: 20
priority: 2
- name: UART1_TX
number: 21
priority: 2
registers:
- name: DATA
offset: 0x00
size: 32
access: read-write
fields:
- name: RX_TX_DATA
bits: [0-7]
- name: PARITY_ERROR
bits: [8]
description: "0 = No error, 1 = Parity error"
# More registers...
timing_constraints:
- description: "Wait at least 1 us after enabling UART before first transmission"
- description: "Maximum baud rate change frequency: 10 kHz"
dependencies:
- "Changing system clock frequency affects UART baud rate"
- "DMA channel 2 can be used for automatic data transfer"
power_modes:
- name: SLEEP
wakeup_sources: [UART1_RX, RTC_ALARM]
- name: DEEP_SLEEP
wakeup_sources: [RTC_ALARM]
# More device-specific details...
IP-XACT
informative? Normative?
It is hard to describe hardware in a way that everyone in the team can understand.
It is hard to describe that same hardware in a way that arbitrary automation tools can parse.
You can decide to draw schematics, or write up an RTL(register transfer Level) description. Maybe a Transaction-Level Modeling (TLM) or even a simulation model for the sake of those who may want to test their understanding through tests. There are so many ways of describing hardware.
Things get more crazy if you are dealing with a complex and unique piece of hardware. You CANNOT just depend on a lengthy reference-manual to describe hardware.
IP-XACT tries to standardize this overwhelm of documents. It creates a more navigable index and description of description docs.
Think of IP-XACT as a document that acts as an index to other description documents.
The different document types are:
- Component
- Design
- Design configuration
- Bus definition
- Abstraction definition
- Type definitions
- Abstractor
- Generator Chain
- Catalog
IP-XACT has more access modes than SystemRDL and UVM. It borrowed a lot from the two.
(This topic is undone.)
Short Notes
- all of its documents are in xml
- It has 9 descriptive documents:
- component
- design
- design configuration
- bus definition
- abstraction definition
- type definitions
- abstractor
- generator chain
- catalog
UVM
SystemRDL
different views of presenting hardware:
- Human description (eg look at the hardware reference manual) - outlines functional and architectural specifications in human language
- Schematics (still falls under human description)
- Behavioural code (describe hardware as an algorithm - inputs, outputs and expected behaviour)
- Register description cpde
- RTL code
- Gate-level code
- Transistor-level code
A regiter description code captures:
- The behaviour of the individual register
- The organization of the registers in memory
- the organization of the registers into register files,
Various variety of register functions:
- Simple storage elements
- storage elements with special read/write behavior (e.g., ‘write 1 to clear’)
- interrupts
- counters
SystemRDL is intended for
- RTL generation
- RTL verification
- SystemC generation
- Documentation
- Pass through material for other tools, e.g., debuggers
- Software development
"SystemRDL was created to minimize problems encountered in describing and managing registers" - what does managing mean?
SystemRDL was meant to provide a single source describing registers. This description will be constant throughout the design, manufacture, testing, abstraction and usage of the piece of hardware.
Process involved in building hardware:
- Human functional and architectural description
- Test/casual Designs (schematics)
- Formalizing (coming up with formal spec views and designs (RTL, GTL, TL, RDL, Headers, PACs, MACs, HALs, ))
- Design Testing/Verification
- Design Implementation/Manufacture
- Post-Testing/Verification
HumanSpec ==> Schematics|Behavioural Code|SystemRDL ==> {RTL, C, Verilog, Rust, Clash, SpinalHDL}
Access Modes
Properties per component
Compiler
- Which versions of SystemRDL does it support?
- Compatibility to future versions?
Examples
// simple explicit/definitive field
field my_custom_field {
};
// simple anonymous field
field {} ;
Needed Tooling
- Conversion to IP-XACT xml
- Automatic documentation
-
Strict SystemRDL {
- makes sure user fills out every component property explicitly (or the intellisense fills things out automatially)
- every instance is explicitly named (no implicit declarations and instantiations)
- address comments are filled automatically (eg reg {} csr; // 0x400 - 0x408)
- no parameter dependence
- no dynamic assignments
- no implicit declarations or instantiations
- No "Arrays may be used as struct members, or in property or parameter declarations.s"
- Where and how is it recommended to define custom properties?
- "Effectively, multi-dimensional arrays are not supported. This limitation may be circumvented by defining arrays of structs containing arrays." - this is not a limitation, design better!
- remove this rule: "When expression is not specified, it is presumed the property_name is of type boolean and the default value
is set to true" - it does not make sense eg
field myField {
rclr; // Bool property assign, set implicitly to true woset = false; // Bool property assign, set explicitly to false name = “my field”; // string property assignment sw = rw; // accesstype property assignment }; ```
- Dont allow this : "swwe and swwel have precedence over the software access property in determining its current access state, e.g., if a field is declared as sw=rw, has a swwe property, and the value is currently false, the effective software access property is sw=r."
}
- Driver generation
- C header generation
- PAC-generator (with Rust style safety)
- Language server (for IDEs)
- VsCode systemRDL support
- Intellisense
- rust-based compiler
- nixos support
Advantages
- "NOTE—Any hardware-writable field is inherently volatile, which is important for verification and test purposes." - this will reduce the number of volatile reads in our PAC, it will allow the compiler to optimize things
- Elaborate reads/write access descriptions :
- description includes both hardware and software access specifications
- descriptions go beyond RW, RO, WOs
- description includes both read and write effects
-
- does not explain register-register effect
-
- does not explain timing costraints
- fddf
Vcell is one of the crates that PAC depends on. In order to understand the PAC, we need to understand :
- What vcell is and how works
- Understand how vcell fits into the PAC crate
What is a cell? Why are we using them?
To wholly understand what a cell is, read up on core::cell.
I'll try my best to explain a watered-down version of it.
In Rust, core::cell is a module that provides a set of types for interior mutability. Interior mutability allows you to mutate data even when you only have an immutable reference to it. This is useful in situations where you need mutability but also need to adhere to Rust's ownership and borrowing rules.
So temporary unrustmanhip.
The types provided are :
Cell<T>RefCell<T>OneCell<T>- Other helper structs/types
These celll enclose types and allow that type to ...
- have multiple
&mut Tand&Tat the same time - be mutated through both
&mut Tand&Treferences
But it is not all chaos... there are rules... some rules on how all these mutiple references work together.
- These types are not multi-thread-safe. They are guaranteed to work ONLY in a single-threaded program. (If you need to do aliasing and mutation among multiple threads,
Mutex<T>,RwLock<T>,OnceLock<T>or atomic types are the correct data structures to do so). - Under Cell
- a
&mut Treference to the inner value can NEVER be obtained. - The inner value
Tcannot just be obtained like that. You have to replace it with another value.
- a
- Under RefCell
(this topic is undone)
Representation
reference : https://doc.rust-lang.org/nomicon/other-reprs.html
- discuss
- why memory representation is immportant in driver development
- The types of memory representation
- #[repr(rust)]
- #[repr(C)]
- #[repr(transparent)]
- #[repr(u8)], #[repr(u16)], #[repr(u32)] // applied to an enum
- #[repr(align(2))]
- When one should use certain memory representations
- defining accurate register alignments/sizes
- FFI-ing
- Look into core::mem and use it to demonstrate the different alignment representations in practical way
What is alignment?
Alignment is the process of placing data in starting addresses that are a multiple of a certain number. For example, if I say that data_x has an alignment of 2, it means that data_x's starting address will be divisible by 2^2. eg address 4.
So why is the divisibility of starting addresses important?
-
Performance: Many hardware architectures, particularly modern CPUs, are optimized for accessing aligned data. Accessing data that is aligned according to the architecture's requirements often results in faster and more efficient memory access. Misaligned data access may require the CPU to perform additional operations or fetch data in multiple memory transactions, leading to decreased performance.
-
Hardware Requirements: Some hardware architectures have strict alignment requirements for certain types of data. Failure to adhere to these requirements can result in hardware exceptions, crashes, or undefined behavior. Aligning data properly ensures compatibility with the target hardware and prevents such issues. For example, the riscv, instructions have an alignment of 5 -referring to the fact that instructions must start at memory addresses that are multiples of 4 bytes. If they are not aligned, the
instruction address misalignedexception will be thrown. -
Atomic Operations: Some atomic operations, such as atomic read-modify-write operations, may require that memory addresses be aligned to specific boundaries. Misaligned data can prevent these operations from being performed atomically, leading to potential data corruption or race conditions in concurrent programs.
-
Portability: Writing code that adheres to memory alignment requirements ensures portability across different hardware architectures and platforms. By following alignment guidelines, code can be more easily ported and maintained on various systems without encountering unexpected behavior or performance issues.
What is minimum alignment?
Minimum alignment refers to the strictest alignment requirement for a particular data type, which is often dictated by the platform's architecture or the ABI (Application Binary Interface).
When we talk about the minimum alignment of a type, we are referring to the smallest power of 2 that the memory address of an object of that type must be divisible by. This is to ensure that the data can be accessed efficiently by the hardware, as many CPUs require certain types to be aligned to specific boundaries for optimal performance.
For example:
If the minimum alignment of a type is 8 bytes, it means that any object of that type must be located at a memory address that is divisible by 8.
Alignments and how they affect space occupied by data-types
Alignment is not directly related to the space occupied by the data type. However, the alignment can influence the amount of space occupied by data in memory, as padding may be inserted between fields of a struct or at the end of an array to ensure that each element meets the required alignment.
for example :
#![allow(unused)] fn main() { // These two structs occupy different sizes even though they have the same field types. // This is because struct::s1 has added paddings to help align field_1 to the alignment of 6 ie (2^6 = u64) // s1 is 16 bytes long // s2 is 12 bytes long #[repr(Rust)] struct s1{ field_1: u32, field_2: u64 } #[repr(packed)] struct s1{ field_1: u32, field_2: u64 } }
repr(transparent)
The #[repr(transparent)] attribute in Rust is used to ensure that a struct has the same memory layout as its single non-zero-sized field. This attribute guarantees that the struct does not introduce any additional padding or alignment requirements beyond what its field requires.
When you apply #[repr(transparent)] to a struct, it ensures that the struct's layout in memory is exactly the same as the layout of its single non-zero-sized field. This can be useful for creating newtypes that wrap existing types but have different behavior or semantics, without introducing any additional overhead in terms of memory layout or performance.
Example :
#[repr(transparent)] struct Wrapper(u32); fn main() { let w = Wrapper(42); println!("Size of Wrapper: {}", std::mem::size_of::<Wrapper>()); println!("Value inside Wrapper: {}", w.0); }
If a struct has multiple fields of different sizes, applying #[repr(transparent)] will result in a compilation error. This is because #[repr(transparent)] can only be applied to structs with a single non-zero-sized field.
This code will produce a compilation error :
#[repr(transparent)] struct Wrapper { field1: u32, field2: u64, } fn main() { let w = Wrapper { field1: 42, field2: 123 }; }
Using core::mem to inspect Representations.
To check the ABI-required minimum alignment of a type in bytes
- exception attribute with re-entrancy guarantees
- zero-cost abstractions?
What should our rules be when dealing with peripherl registers?
How can we reliably interact with these peripherals?
- Always use volatile methods to read or write to peripheral memory, as it can change at any time
- In software, we should be able to share any number of read-only accesses to these peripherals
- If some software should have read-write access to a peripheral, it should hold the only reference to that peripheral
We cannot use global mutable variables because they expose our peripheral to every software. We just want one software to have the mutable reference to a single peripheral. Every other software should have read_references.
There should ONLY BE ONE mutable instance of a peripheral.
That is why we use the Singleton.
Pointer manipulations
Be afraid of implicit copies. Just use ONE value assignation and multiple references when dealing with pointers that point to ONE physical memory address.
As you can see below, x and y have different addresses.
#![allow(unused)] fn main() { let x = 10; let y = x; println!("Address of x = {}", (&x as *const i32) as usize); // Address of x = 140735333354256 println!("Address of y = {}", (&y as *const i32) as usize); // Address of y = 140735333354260 }
ONE ASSIGNATION, the rest should be references.
TWO ASIGNATIONS result in two different raw addresse....
Building the UART on qemu
This chapter elaborates on how to write a UART driver for a virtual UART emulated by the Qemu machine emulator.
The UART in this chapter is naive. It does not use standard & safe abstractions. It is also blocking in nature.
The UART covered in the next-next chapter will be an improved of the UART covered in this chapter.
Qemu
QEMU is a generic and open source machine emulator and virtualizer.
A machine emulator is a software program that simulates the behaviour of another computer or another computing system. For example you may simulate the behavior of a quantum computer on a convetional computer.
A virtualizer is a program that abstracts away an underlying system. The underlying system can be anything : Bare metal cpu, a hard disk, an operating system... anything.
QEMU can be used in several different ways. The most common is for System Emulation, where it provides a virtual model of an entire machine (CPU, memory and emulated devices) to run a guest OS. In this mode the CPU may be fully emulated, or it may work with a hypervisor such as KVM, Xen, Hax or Hypervisor.Framework to allow the guest to run directly on the host CPU.
The second supported way to use QEMU is User Mode Emulation, where QEMU can launch processes compiled for one CPU on another CPU. In this mode the CPU is always emulated.
In our project, we will use Qemu as a Riscv System Emulator.
Templates (hints)
The next few chapters are going to be about setting things up. At the end of each sub-chapter, you will see a link to a finished template containing a cargo project that has been modified in accordance to the concerned sub-chapter.
The templates are not guaranteed to be always compile-worthy. They are meant to act as Hints -- Not copyable short-cuts. Try to understand them before moving on. Examine them, things will click with time.
Setting Things Up
Under this chapter, we intend to answer the following 3 questions :
- What are we setting up?
- Why are we setting up those things?
- How are we seting up those things?
What are we setting up?
We are setting up the following components :
- A development toolchain
- A RISCV virtual environment
- A no-std Rust file.
The development Toolchain
A toolchain is a group of software tools that typically get used together...a chain of tools...
In OS Development, the name toolchain usually refers to the combination of the compiler, linker, debugger and a bunch of programs that help in inspecting files. This toolchain gets used to convert source code into a format that can run on an execution environment.
An execution environment is a place where a software program can run. It provides the necessary resources, like the operating system and libraries, that the program needs to function. Examples of execution enviroments include: Bare metal, Browsers, Virtual Machines, Operating systems and Containers.
The toolchain in our case will consist of the following tools :
- The Rust Nightly Compiler with a riscv64gc-unknown-none-elf backend
- linker : Rust-lld
- Binutils
To our luck, we do not have to install all these elements seperately. There exists compact toolchains :
- LLVM Riscv toolchain (ignore for now)
- The GNU Riscv Toolchain (ignore for now)
- The Rust Toolchain
Why we need the toolchain
We will have two kinds of source code files in our project : Rust source files and RISCV-Assembly files. Both of these types of files need to be turned into object files. Afterwards, those object files need to get linked together into a single executable file.
To do all this, we need a compiler and a linker that can do cross-procesing.
We can go about this process of creating a single executable file in two ways:
Method 1
We can compile the Rust files seperately from the Assembly files.
Meaning that we will do the following actions in order :
- Use a stand-alone assembler to assemble the RISCV assembly files and turn them into object code.
- Compile the RUST files into object code using a RUST_compiler.
- Combine the all the resultant object files from the above 2 steps using a linker to form a single executable.
Method 2
We can embed the assembly code into the Rust source code.
That way, we only need one compilation, we will only need to compile the asm_embedded Rust files using the rust compiler. This method seems more of 'plug and play' because it does not need us to have a seperate riscv-asembler. It only requires us to have a rust-compiler only.
The disadvantage of this method is that we will always have to re-compile our entire project each time we change anything in any source file. But this is not really a problem; modern compilers are Fast, recompiling every file in our project is a matter of seconds.
Using method one will save up a few nano_seconds. A few nanoseconds is cheap price to pay.
Method 2 is a more user friendly method. Trading off negligible compile time over a user-friendliness in building and tweaking configurations is by far a very good choice.
Moreover, the rust compiler comes with its own inbuilt LLVM linker, rust-lld. That means that once we hit compile, we get the executable file output. One click, and all the build process runs inbuilt; from compiling rust files, to compiling assembly files, to creating a riscv-compliant executable file.
No more Makefiles nightmares, no more. This is very big news.
For this reason, we will use Method 2.
Setting Up the Compiler
The compiler is the tool that will convert our source code to machine code that suits a specific machine target.
In our case, that specific machine target is riscv64gc-unknown-none-elf. ie "The RISCV CPU, bare metal".
The rust compiler gets installed as a toolchain, so it comes with a linker attached. For this reason, our compile button will do the following :
- Compile rust files
- Compile the embedded assembly files.
- Link all the object files and produce an executable ELF file. (linker part)
Ofcourse you can use a 3rd-party linker that you prefer, you are not forced to use the attached linker. But using another linker looks like a lot of unnecessary hard work tbh.
In the compiler world, people identify compilation targets using a standard naming convention called "Target Triple".
Initially the Target triple specified three characteristics of the machine target :
- CPU Architecture : eg x86, RISCV, ARM
- Vendor who manufactures the target : eg Apple, IBM
- The operating system running on the CPU : eg Linux, Windows, FreeBSD, None
For example you would define a target as : ARM-Apple-IoS
But the world got more complex, now we have people naming things like... i don't know... it is not 3 characteristics anymore. Sometimes you have 2 sometimes 5, 4 or 3.
So here is a 4 identifier description :
- CPU architecture
- Vendor
- Operating System
- ABI
Really, there is confusion, but hopefully you can tell what stands for what when you see a triple target with a weird number of identifiers.
Commands
To install the Stable Rust compiler, enter the following comand :
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
Alternatively, you can visit this page : Rust Compiler installation Main Page
Our project will use Nightly features. So you will need to install Rust Nightly :
rustup toolchain install nightly # install nightly Compiler
rustup default nightly # set nightly Compiler as the default toolchain
The Machine Target we are compiling for is "riscv64gc-unknown-none-elf" which means we are compiling for
- "riscv646gc - 64-bit-Riscv CPU that supports all general instructions ('g') and supports compressed instructions ('c')
- unknown - means that the manufaturer of the CPU is unknown or that info is irrelevant
- none - means that the CPU has no operating system running on top of it
- elf - This component identifies the format of the output binary file that will be generated by the compiler. In this case, it specifies that the binary file will be in the ELF (Executable and Linkable Format) format, which is a common format used for executables and shared libraries on Unix-based systems.
To check out all the targets that the compiler can support by default, type the following command :
rustup target list # list all supported targets
rustup target list --installed # list all installed supported targets
To install our riscv64gc-unknown-none-elf target, enter the following command ;
rustup target add riscv64gc-unknown-none-elf # install a supported target
Recap on writing a bare_metal_rust_executable
1. NO_STD
A bare metal executable is a rust program that can run on a piece of hardware without needing an operating system.
Since we are building a driver, we need to write it as a program that is not dependent on an operating system.
Normal Rust programs depend on the rust standard library. The Rust standard library itself contains functions that call OS-specific system calls. So we cannot use the Rust std library.
We use the core Rust Library which is not environment-specific. The core library is dependency-free. It's only requirement is that the programmer provides the definitions of some linker symbols and language items.
To disable the std-dependence, we add the crate attribute #![no_std] to our project.
2. NO_MAIN
Libc is a common C standard library that has been in use for a long time. It has been implemented for very many operating systems.
Rust is a new language. It is very hard to implement the rust_std for all operating systems. To save on labour and allow compatibility, Rust creators decided to make the Rust Library to use libC functions instead of recreating the functions in pure Rust. Though there are some parts of the Rust std library that do not depend on libc.
Now that it is clear that rust_std depends on libc, when a rust bin is executed, the following events happen.
- The executable program is stored in the main memory (eg RAM)
- The CPU points to the first instruction of the executable (the entry point). In this case, the entry point is the
_startfunction found in the C runtime. - The C runtime sets up its environment in preparation for the libc functions that will get called by the rust_std functions
- After the C runtime has set up the execution environment for the libc functions, it points to the entry point of the Rust Runtime.
- The entry point of the Rust Runtime is marked with a language item called "start" ie [start]
- So the Rust runtime creates an executable environment for executing the Rust functions.
- After the Rust runtime has finished setting up things, it looks for the "main" function.
- Main starts executing
Our bare metal program does not depend on the C runtime. So this sequence of events is quite irrelevant to us.
What we will do is that we will inform the compiler that we wont follow this sequence by :
- Adding the
#![no_main]crate attribute to our project. - Declaring our own entry point function
To declare our own entry point, we will export a function out of the crate... like so :
#![allow(unused)] fn main() { #[no_mangle] // The no_mangle attribute explained below pub extern "C" fn _start() // Mangling is a technique used by compilers to encode the names of // functions, methods, and other symbols in a program in a way that includes additional information beyond just the name itself. // For example `main` may become `main21212jxbjbjbkjckbdsc&kbjbjksdbdjkbf` // The primary purpose of mangling is to make sure that each variable or function is completely unique to // the point that there are no name-conflicts during compilation and linking. // This also enables function overloading //In Rust, the #[no_mangle] attribute is used to instruct the compiler not to mangle the name of the item ... // (function or static variable) during compilation. This is useful when you want to interface with external // code, like C code or assembly code, where the function names need to remain unchanged. // We want "_start" to be referenced as it is. We cannot gamble with the identity such a symbol name }
But that is not enough, we need to tell the linker the name of our entry_point function. We do this by writing a linker script that uses the ENTRY command.
The linker will place the code as the first part of the .text section and update the elf header sections to reflect this info.
...
OUTPUT_ARCH( "riscv" )
ENTRY( _start ) /* See? we have used the name `_start` just like it is. If name mangling had happened, we would have had some random name that changes with every compilation.
MEMORY
{
ram : ORIGIN = 0x80000000, LENGTH = 128M
}
3. Panic Handler
Rust runtime panics when a violation happens. Rust requires you to define a function that will always get called after a panic happens.
That function is tagged by the #[panic_handler] attribute.
The panic_handler function never returns anything, it diverges. It is therefore a divergent function.
#![allow(unused)] fn main() { use core::panic::PanicInfo; #[panic_handler] fn my_custom_function( panic_info: &PanicInfo)-> !{ println!("message : {}", panic_info.message()) println!("location : {}", panic_info.location()) } }
4. The eh_personality (aka error_handling personality)
Rust requires you to define a function that will always get called when it wants to unwind and free a stack.
This function is tagged with #[eh_personality] attribute.
When a panic happens, the program stops (theoretically). The program can decide to free the stack or just abort and let the underlying OS clear the stack.
The thing is, to clear the stack, you have to unwind it. To unwind the stack, you have to use some hard functions...Functions that depend on some OS functionalities. This is a chicken-egg problem.
So we resort to aborting.
To specify this behaviour, you can tweak the cargo file as follows :
[profile.release]
panic = "abort"
[profile.dev]
panic = "abort"
By default the settings are usually :
[profile.release]
panic = "unwind"
[profile.dev]
panic = "unwind"
Now, the #[eh_personality] tag is a tag that is pegged to the function that gets called when a rust program wants to unwind its stack. eg
#![allow(unused)] fn main() { #[eh_personality] fn custom_unwind(){ // do some unwinding statements ... MAgiC! } }
BUT since we have specified that our program will always abort... AND that it will never call the unwind function, we are no longer required to define the unwinding function
5. Compile for a bare_metal target
You can now compile for the speific target that you want. In our case, it is the riscv64-unknown-none-elf.
To get a recap on how to perform cross-compiltion, re-visit this chapter
Template Link
You can view the template folder here.
Setting up the Riscv Virtual environment
We will be using the Qemu RISC-V System emulator to emulate a RISCV-CPU microcontroller.
Installation
To install Qemu, input the following terminal commands
sudo apt install qemu-user
sudo apt install qemu-system-misc
Qemu Configurations
1. Machine to be emulated
For QEMU’s RISC-V system emulation, you must specify which board model you want to emulate with the -M or --machine Qemu-configuration option; there is no default machine selected.
In our case, we will emulate the ‘virt’ Generic Virtual Platform as our target board model.
2. Booting mode
When using the sifive_u or virt machine there are three different firmware boot options:
-bios default- This is the default behaviour if no -bios option is included. This option will load the default OpenSBI firmware automatically. The firmware is included with the QEMU release and no user interaction is required. All a user needs to do is specify the kernel they want to boot with the -kernel option-bios none- QEMU will not automatically load any firmware. It is up to the user to load all the images they need.-bios <file>- Tells QEMU to load the specified file as the firmware.
We will use the following Qemu configurations ;
# let's define some variables
QEMU=qemu-system-riscv64 # we are using the Riscv Qemu emulator. qemu-system-riscv64 is a variable containing the path to the QEMU executable
MACH=virt # we will target the Virt Riscv Machine
CPU=rv64 # we will use a 64-bit CPU
CPUS=4 # The Board will have 4 CPUs... 4 HARTS
MEM=128M # The RAM memory will be 128 MBs
# DRIVE=hdd.dsk // This is the path to our virtual harddrive
# Let's substitute the above variables into Qemu-configuration options
$(QEMU) -machine $(MACH)
-cpu $(CPU)
-smp $(CPUS) # specifies the number of CPUs to emulate
-m $(MEM) # specifies the amount of RAM in MBs
-nographic # disables graphical output, so QEMU runs in a terminal window.
-serial mon:stdio # connects the virtual machine motherboard's serial port to the host's system terminal. Ie, our Linux terminal. This enables us to use the terminal as a console to the virtual machine.
-bios none # we not depend on any firmware becaue our machine is virtual. We can just direclty load the kernel image to memory.
-kernel $(OUT) # This specifies the path to the loader/driver/kernel image file
So whenever we run a Qemu emulation, we should run it with the above config files
Template
There is no template for this subchapter. Try writing the qemu commands by hand before we integrate them to cargo.
Setting up the linker
References :
As earlier mentioned, the Rust compiler comes with an inbuilt linker. Each target comes with its own configured linker.
So by default we do not need a linker script. But for our case, we need a linker script.
So Why do we need a custom linker script?
Reason 1 : To define the Entry-Point
Every program has an entry_point function.
An entry point is the place in a program where the execution of a program begins. Where the program-counter of the CPU will initially point to if it wants to run that program.
For example, Normal Rust programs that depend on the std library normally have their entry-point defined as '_start'. This "_start" function is typically defined as part of the C-runtime code.
In our case, the default linker used for the riscv64-unknown-none-elf automatically sets the entry point by trying each of the following methods in order, and stopping when one of them succeeds:
- The ` -e ' entry command-line option;
- The ` ENTRY (symbol) ' command in a linker script;
- The value of the symbol, start, if defined;
- The address of the first byte of the ` .text ' section, if present;
- The address,
0in memory '.
To avoid unpredictable behavior, we will explicitly declare the entry point in the linker script.
Reason 2: To define your own KNOWN memory addresses
Here is the thing, an elf file has many sections and symbols; the global_data section, the heap, the stack, the bss, the text section...
To write driver-level code, you need to explicitly KNOW the exact memory addresses of different elf sections and symbols. You need to KNOW the exact memory address for a particular function. You need to KNOW the exact memory address for the register that you want to read from. You need to KNOW the exact memory addresses for a lot of things....
For example....
when you want the driver-loader to load the driver, you may have to make the CPU instruction-pointer to point to the entry_point of the driver, you will need to give the driver-loader the exact memory address of the entry_point. Or maybe give it the address of the text_section.
Point is, to write driver code, you need to know the exact memory addresses of the different sections in your code in memory.
The linker script lets you define the exact memory addresses for the different elf sections and points. And the good thing is that the linker lets you label this known memory points using variables ie. symbols.
Using the default linker script is wild; You let the linker decide the memory addresses for you.
This means that you would have to constantly change your code to point to the addresses the linker chose for you. And the linker is not that deterministic. Today it places the heap here, tomorrow there.
So it is best to define your own linker script that explicitly defines memory addresses that you KNOW.
"Reject unpredictability, Embrace predictability" - Zyzz
Reason 3: Memory Alignment
You may want to make sure the different elf sections and symbols are aligned to a certain multiple. For example, if you plan to divide the Register mappings into 8-byte blocks, you may prefer to make the register_start memory address a multiple of 8
End of reasons...
So how do we write a Linker Script? And which linker are we scripting for?
Which linker are we scripting for?
The rust gives you an option to choose whichever linker you want to use.
Rust uses the LLVM Linker by default. So we are currently scripting for the LLVM Linker.
You may want to use other linkers based on your usecase. For example the LLVM linker is known for its advanced optimizations. The gold linker is optimized for elf files only, so it is lightweight and faster than the GNU linker. Meaning that you will not prefer the gold linker when creating non_elf files.
To know which linker version you are currently using, you can enter the command below :
rustc --version --verbose
You get a result like this :
rustc 1.70.0-nightly (f63ccaf25 2023-03-06)
binary: rustc
commit-hash: f63ccaf25f74151a5d8ce057904cd944074b01d2
commit-date: 2023-03-06Unleashed, this is the
starting memory address for our code
host: x86_64-unknown-linux-gnu
release: 1.70.0-nightly
LLVM version: 15.0.7
From the above result, you can see That LLVM linker is used and specifically version 15.0.7
But each target uses a particular linker flavour, what if you want more information about your current host target? What if you want information about another non_host target? Use the following command :
rustc +nightly -Z unstable-options --target=wasm32-unknown-unknown --print target-spec-json # for the nightly compiler
# OR
rustc -Z unstable-options --target=riscv64gc-unknown-none-elf --print target-spec-json #for the stable compiler
You can optionaly specify your linker of choice in the build manifest file (configuration file) - cargo.toml as follows :
[target.'cfg(target_os = "linux")'.llvm]
linker = "/usr/bin/ld.gold" //this specifies the path to the gold linker
But this is hard work, we are not taking that path. The less configurations we do, the more portable our code, the less headaches we get.
So let's just use LLVM. For this project, ignore gold, GNU or any other linker.
How do we write a Linker Script?
You can follow this tutorial here
- Tell the linker which architecture you are targeting
- You define the entry address of the elf file
- Define all the memory that we have : RAM and ROM or just one of them
The linker functions include : - Resolving External symbols - Section Merging - Section Placement
We are writing the linker script so that we can instruct the linker on how it will do the section merging and section placement.
Section merging is the process of combining similar elf sections from different files: For example if A.o and B.o were to be linked together to form C.o, then the linker will merge the .text section from both A and B and put the merged output into C ie. A.text_section + B.text_section = C.text_sectiob.
Section placement is the process of specifying the virtual address of the different sections within the elf file. For example you may place the text section at 0x00 or 0x800... you name it. By default the linker places the different segments in adjacent to each other... but if you do this section placement process manually, you can set paddings between segments or jumble things up.
Exercise
Write a linker script for the ‘virt’ Generic Virtual Platform.
The memory layout for the virtual board can be found here.
Come up with a linker script, even if it doesn't work. Try to figure it out.
You can use the example below.
Below Linker script example that you can use for hints:
/*
define the architecture of the target that you are linking for.
for any RISC-V target (64-bit riscv is the name of the architectut or 32-bit).
We will further refine this by using -mabi=lp64 and -march=rv64gc. But this will do for now. s
*/
OUTPUT_ARCH( "riscv" )
/*
We're setting our entry point to a symbol
called _start which is inside of loader.s . This
essentially stores the address of _start as the
"entry point", or where CPU instructions should start
executing.
In the rest of this script, we are going to place _start
right at the beginning of 0x8000_0000 because this is where
the virtual machine and many RISC-V boards will start executing.
*/
ENTRY( _start )
/*
The MEMORY section will explain that we have "ram" that contains
a section that is 'w' (writeable), 'x' (executable), and 'a' (allocatable).
We use '!' to invert 'r' (read-only) and 'i' (initialized). We don't want
our memory to be read-only, and we're stating that it is NOT initialized
at the beginning.
The ORIGIN is the memory address 0x8000_0000. If we look at the virt
spec or the specification for the RISC-V HiFive Unleashed, this is the
starting memory address for our code.
Side note: There might be other boot ROMs at different addresses, but
their job is to get to this point.
Finally LENGTH = 128M tells the linker that we have 128 megabyte of RAM.
The linker will double check this to make sure everything can fit.
The HiFive Unleashed has a lot more RAM than this, but for the virtual
machine, I went with 128M since I think that's enough RAM for now.
We can provide other pieces of memory, such as QSPI, or ROM, but we're
telling the linker script here that we have one pool of RAM.
*/
MEMORY
{
ram (wxa!ri) : ORIGIN = 0x80000000, LENGTH = 128M
}
/*
PHDRS is short for "program headers", which we specify three here:
text - CPU instructions (executable sections)
data - Global, initialized variables
bss - Global, uninitialized variables (all will be set to 0 by boot.S)
The command PT_LOAD tells the linker that these sections will be loaded
from the file into memory.
We can actually stuff all of these into a single program header, but by
splitting it up into three, we can actually use the other PT_* commands
such as PT_DYNAMIC, PT_INTERP, PT_NULL to tell the linker where to find
additional information.
However, for our purposes, every section will be loaded from the program
headers.
*/
PHDRS
{
text PT_LOAD;
data PT_LOAD;
bss PT_LOAD;
}
/*
We are now going to organize the memory based on which
section it is in. In assembly, we can change the section
with the ".section" directive. However, in C++ and Rust,
CPU instructions go into text, global constants go into
rodata, global initialized variables go into data, and
global uninitialized variables go into bss.
*/
SECTIONS
{
/*
The first part of our RAM layout will be the text section.
Since our CPU instructions are here, and our memory starts at
0x8000_0000, we need our entry point to line up here.
*/
.text : {
/* In the GNU Linker Script Language, the PROVIDE keyword instructs the linker to declare a new symbol and assign it a value
PROVIDE allows me to create a symbol called _text_start so
I know where the text section starts in the operating system.
This should not move, but it is here for convenience.
The period '.' tells the linker to set _text_start to the
CURRENT location ('.' = current memory location). This current
memory location moves as we add things.
*/
PROVIDE(_text_start = .);
/*
We are going to layout all text sections here, starting with
.text.init.
The asterisk in front of the parentheses means to match
the .text.init section of ANY object file. Otherwise, we can specify
which object file should contain the .text.init section, for example,
boot.o(.text.init) would specifically put the .text.init section of
our bootloader here.
Because we might want to change the name of our files, we'll leave it
with a *.
Inside the parentheses is the name of the section. I created my own
called .text.init to make 100% sure that the _start is put right at the
beginning. The linker will lay this out in the order it receives it:
.text.init first
all .text sections next
any .text.* sections last
.text.* means to match anything after .text. If we didn't already specify
.text.init, this would've matched here. The assembler and linker can place
things in "special" text sections, so we match any we might come across here.
*/
*(.text.init) *(.text .text.*)
/*
Again, with PROVIDE, we're providing a readable symbol called _text_end, which is
set to the memory address AFTER .text.init, .text, and .text.*'s have been added.
*/
PROVIDE(_text_end = .);
/*
The portion after the right brace is in an odd format. However, this is telling the
linker what memory portion to put it in. We labeled our RAM, ram, with the constraints
that it is writeable, allocatable, and executable. The linker will make sure with this
that we can do all of those things.
>ram - This just tells the linker script to put this entire section (.text) into the
ram region of memory. To my knowledge, the '>' does not mean "greater than". Instead,
it is a symbol to let the linker know we want to put this in ram.
AT>ram - This sets the LMA (load memory address) region to the same thing.this linker script, we're loading
everything into its physical location. We'll l LMA is the final
translation of a VMA (virtual memory address). With et the kernel copy and sort out the
virtual memory. That's why >ram and AT>ram are continually the same thing.
:text - This tells the linker script to put this into the :text program header. We've only
defined three: text, data, and bss. In this case, we're telling the linker script
to go into the text section.
*/
} >ram AT>ram :text
/*
The global pointer allows the linker to position global variables and constants into
independent positions relative to the gp (global pointer) register. The globals start
after the text sections and are only relevant to the rodata, data, and bss sections.
*/
PROVIDE(_global_pointer = .);
/*
Most compilers create a rodata (read only data) section for global constants. However,
we're going to place ours in the text section. We can actually put this in :data, but
since the .text section is read-only, we can place it there.
NOTE: This doesn't actually do anything, yet. The actual "protection" cannot be done
at link time. Instead, when we program the memory management unit (MMU), we will be
able to choose which bits (R=read, W=write, X=execute) we want each memory segment
to be able to do.
*/
.rodata : {
PROVIDE(_rodata_start = .);
*(.rodata .rodata.*)
PROVIDE(_rodata_end = .);
/*
Again, we're placing the rodata section in the memory segment "ram" and we're putting
it in the :text program header. We don't have one for rodata anyway.
*/
} >ram AT>ram :text
.data : {
/*
. = ALIGN(4096) tells the linker to align the current memory location (which is
0x8000_0000 + text section + rodata section) to 4096 bytes. This is because our paging
system's resolution is 4,096 bytes or 4 KiB.
As a result, the current memory address is rounded off to the next nearest address that has a value that is a multiple of 4096
*/
. = ALIGN(4096);
PROVIDE(_data_start = .);
/*
sdata and data are essentially the same thing. However, compilers usually use the
sdata sections for shorter, quicker loading sections. So, usually critical data
is loaded there. However, we're loading all of this in one fell swoop.
So, we're looking to put all of the following sections under the umbrella .data:
.sdata
.sdata.[anything]
.data
.data.[anything]
...in that order.
*/
*(.sdata .sdata.*) *(.data .data.*)
PROVIDE(_data_end = .);
} >ram AT>ram :data
.bss : {
PROVIDE(_bss_start = .);
*(.sbss .sbss.*) *(.bss .bss.*)
PROVIDE(_bss_end = .);
} >ram AT>ram :bss
/*
The following will be helpful when we allocate the kernel stack (_stack) and
determine where the heap begins and ends (_heap_start and _heap_start + _heap_size)/
When we do memory allocation, we can use these symbols.
We use the symbols instead of hard-coding an address because this is a floating target.
Floating target means that the address space layout keeps on changing, do it becomes hard to hardcode physical adresses.
The heap size is not known at compile time
As we add code, the heap moves farther down the memory and gets shorter.
_memory_start will be set to 0x8000_0000 here. We use ORIGIN(ram) so that it will take
whatever we set the origin of ram to. Otherwise, we'd have to change it more than once
if we ever stray away from 0x8000_0000 as our entry point.
*/
PROVIDE(_memory_start = ORIGIN(ram));
/*
Our kernel stack starts at the end of the bss segment (_bss_end). However, we're allocating
0x80000 bytes (524 KiB) to our kernel stack. This should be PLENTY of space. The reason
we add the memory is because the stack grows from higher memory to lower memory (bottom to top).
Therefore we set the stack at the very bottom of its allocated slot.
When we go to allocate from the stack, we'll subtract the number of bytes we need.
*/
PROVIDE(_stack = _bss_end + 0x80000);
PROVIDE(_memory_end = ORIGIN(ram) + LENGTH(ram));
/*
Finally, our heap starts right after the kernel stack. This heap will be used mainly
to dole out memory for user-space applications. However, in some circumstances, it will
be used for kernel memory as well.
We don't align here because we let the kernel determine how it wants to do this.
*/
PROVIDE(_heap_start = _stack);
PROVIDE(_heap_size = _memory_end - _stack);
}
Template
You can view the template folder here.
Setting up the Build automation tool
Our build tool will be cargo.
We will not use third party build tools like Makefiles.
It is better to not use 3rd parties.
So create a .cargo folder withing the repo.
Create a config.toml inside the folder
So you have : project/.cargo/config.toml. Inside this file, paste the following configurations :
[build]
target = "riscv64gc-unknown-none-elf"
rustflags = ['-Clink-arg=-Tsrc/lds/virt.lds']
[target.riscv64gc-unknown-none-elf]
runner = "qemu-system-riscv64 -machine virt -cpu rv64 -smp 4 -m 128M -serial mon:stdio -nographic -bios none -kernel "
The [build] section has configs that affect the compilation process. We tell the compiler our target platform. And tell the linker the path to the linker script.
The [target.riscv64gc-unknown-none-elf] section has the configs that will be considered only if we are compiling for the riscv64gc-unknown-none-elf target.
The "runner" specifies the cmd command that will be executed when we call "Cargo run". There is a space after -kernel. This is because cargo will automatically specify the executable, whose name is configured through Cargo.toml.
Template
You can view the template folder here.
Loaders and Bootloaders
Now that we have written a compile-worthy no-std binary... what next?
We cannot just run a driver on metal like that. We need to have a program that boots up the machine before running our driver(our no-std file).
And for this purpose, we introduce two new parties : Loaders and Bootloaders.
Our firmware needs to get loaded into memory by either the Loader or the Bootloader.
Difference between a loader and a bootloader.
A loader and a bootloader are both involved in the process of loading software into memory(*RAM) for execution, but they serve different purposes and operate at different stages of the system startup process.
Bootloader:
A bootloader is a small program that is executed when a computer system is powered on or restarted. Its primary function is to initialize the hardware, perform basic system checks, and load the operating system into memory for execution.
Bootloaders are typically stored in a specific location on the storage device (e.g., the Master Boot Record on a hard disk drive or in the boot ROM of an embedded system).
The bootloader is responsible for locating the operating system kernel, loading it into memory, and transferring control to the kernel to begin the boot process.
Examples of bootloaders include GRUB (Grand Unified Bootloader) and U-Boot (Universal Bootloader), which are commonly used in Linux systems.
But in our case, since we do not have a kernel in sight, the bootloader will load our no-std file. Our no-std file will act as a temporary kernel... or rather, it will act as an execution runtime that can call the UART driver whenever it is needed.
Loader:
A loader, also known as a program loader, is a component of an operating system that loads executable files from storage(eg SSD) into memory(eg RAM) and prepares them for execution.
Loaders operate after the operating system kernel has been loaded and initialized by the bootloader. They are responsible for loading user-space programs, shared libraries, and other executable files as needed during the runtime of the system.
Loaders perform tasks such as resolving external references, allocating memory for program code and data, setting up the program's execution environment, and transferring control to the entry point of the program.
In some cases, the term "loader" may also refer to a component of a development toolchain responsible for generating executable files from source code by linking together various object files and libraries.
So in our case, the loader will a part of the execution runtime (ie our no-std file that was acting as a minimal kernel)
The loader will have the following functions :
- listen for loading & unloading orders from the minimal-kernel
- execute the the loading and unloading.
Loading a program involves things such as ;
- copying the Program's loadable-elf-sections from ROM/HDD/SDD and putting them in the RAM.
- adjusting the necessary CPU registers. For example, making the Program counter to point to the entry point of the program that needs to be loaded.
- Setup stack-protection (if necessary)
- Ensuring that the metadata for the program is available for the minimal-kernel.
Unloading a program involves things such as :
- cleaning the program stack and zeroing out any 'confidential' program sections to avoid data-stealing.
- adjusting the necessary CPU registers. For example, making the Program counter to point back to the minimal kernel
Bootloaders in Qemu-Riscv Virt machine
When using the sifive_u or virt machine in Qemu, there are three different firmware boot options:
-bios default # option 1
This is the default behaviour if no -bios option is included. This option will load the default OpenSBI firmware automatically. The firmware is included with the QEMU release and no user interaction is required. All a user needs to do is specify the kernel they want to boot with the -kernel option.
-bios none # option 2
QEMU will not automatically load any firmware. It is up to the user to load all the images they need.
-bios <file> # option 3
Tells QEMU to load the specified file as the firmware.
The Bootloader
Since we are not booting the typical kernel, let us stop using the term bootloader. let's use the word start-up code.
Calling it bootloader implies that it does esoteric functions such as performing a power-on self test and loading secondary loaders. So we will stick to the name startup code.
The startup code does the following actions :
- It describes a function that helps us find the correct exception handlers. Something like an
switchfor exception-handling functions - Chooses a HART/CORE that will execute the rest of the activities below
- Copies all initialized data from FLASH to RAM.
- Copies all un-initialized data from FLASH to RAM.
- Zeroes-out all the un-initialized data
- Sets up the stack pointer
- Calls the
mainfunction in our rust code
Our start-up code will be written in Riscv Assembly.
We will embed those assembly files as part of our rust files.
You can find books to help you learn riscv in the reading_resources folder
Template
You can view the template folder here.
undone:
- fuzzing
- unit testing
- integration testing
- formal verification
- performance testing
- concurrency testing
remember miri, loon, criterion
Probing
Probing is the act of interacting with the microcotroller with the aim of doing at least one of the following...
-
Flashing a compiled program onto the RAM or ROM of the microcontroller. ie. writing your code into the RAM or ROM... breathing life into the machine.
-
Performing some In-system programming ie. literally manipulating the values found in the processor's registers and occasionaly reading and writing to memory.
-
Debugging the running program : Observing the how the program state changes in a step by step fashion.
-
Testing the functionality of the microcrontroller
This chapter walks through the theory behind first 3 tasks while assuming that...
- Your host machine is a linux box
- Your target machine is an esp32c3 SoC.
The practicals will be covered in a later chapter.
Probing Theory
What is probing really? How is it achieved? What's flashing? What's in-system programming? What's Debugging?
Probing
Probing is the act of interacting with a microcontroller... or a device that does not have a comprehensive User Interface.
Interacting may mean one of the following :
- In-system programming - this is the process of accessing the RAM and ROM of components in the SoC in such a way that you can change the firmware code.
- Monitoring - this is the act of fetching data on the events happening in the SoC for the sake of maybe debugging.
- Flashing - Flashing is a fancy name for : "using in-system programming to wipe out all the current firmware in the memory and replacing them with fresh new lines"
- SoC testing (eg boundary scan testing) - this is the act of testing whether the circuitry of the SoC works as expected.
How are probing devices able to interact with a chip?
"A probing device is able to interact with a chip because the probe device interfaces with the boundary-scan interface present on the chip." --- this is a mouthy sentence... let's break it down with a lot of stories.
An SoC is made up of circuits. To test whether the circuits worked as expected, the designers of the past used to use test fixtures but with time they settled for using on-chip test circuits.
A popular and standard example of on-chip test circuitry is the Boundary-scan.
With time, it became clear that boundary scans could control and affect how the SoCs worked if connected properly. They could even be used to read and write to the RAM and ROM if attached to the DMA controller. They could be used to monitor the signals coming in and out of the Core. They could be used to inject stub data to the pins of the core and thus manipulate the core itself... Boundary-scans became the holy-grail of monitoring and manipulating SoCs.
With time people came up with boundary scan standards that roughly specified :
- How the circuitry was hooked up in a way that integrates with the circuitry that is getting tested. In way that it does not change the functionality of the circuit being tested.
- How the physical interface between the scan and external probes was to be implemented.
- The communication protocol between the scan and external probes.
One open and standardized boundary scan is called the JTAG standard.
There is also another proprietary on-chip test circuitry called SWD.
All this info might not make sense on the go...
Go watch this video by EEVBlog, it puts things into persective. He's a good teacher.
After that video, you might want to get your definitions and structures right by reading a more formal but simple technical guide by the xjtag organization.
By the end of all that reading and video-watching, the figure below should make total sense... in fact, you should be very very mad because it misses out on some important components :
The Probe/ Debug Adapter
From here on, the term JTAG will be used as a synonym for Boundary-scan-circuit.
The probe/debug adapter is the physical device that connects a normal computer to the JTAG interface. This is because the JTAG interface is not directly compatible to the ports found on a normal computer. For example the USB port found on a computer cannot directly connect to the 4 pins of the JTAG port.
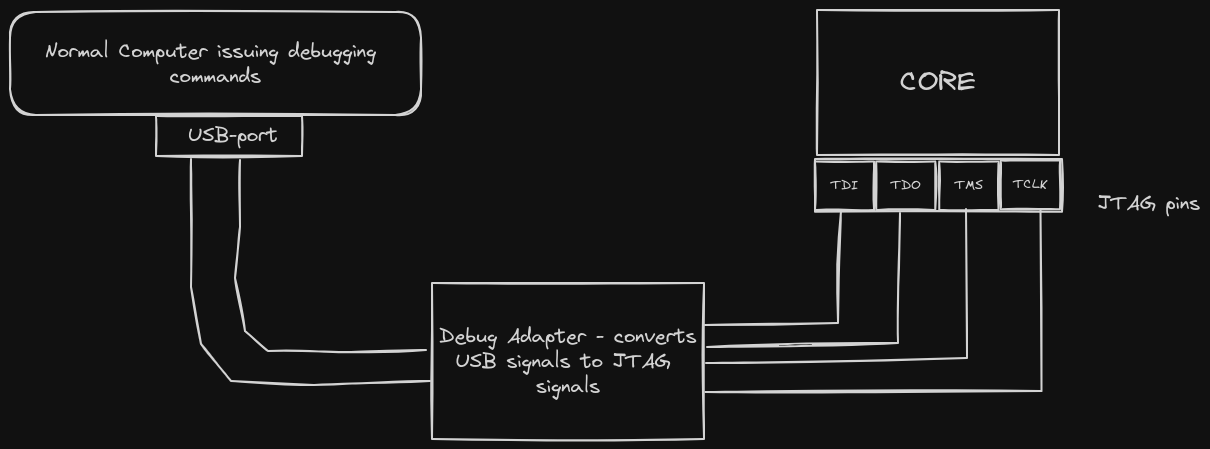
From the above image....
The normal computer contains debugging software that issues out debugging commands. For example : "command : pause the program execution". These commands get sent out as usb-signals.
The normal computer sends out USB signals to the debug adapter. The Debug adapter receives the usb-signals via the USB-port.
Upon receiving the usb-signals, the debug adapter converts those usb-signals into JTAG-signals. The jtag-signal then get sent out via the 4 pins that have been attached to the JTAG-interface found at the core.
Open-OCD and its alternatives
So how does the host computer know which signals to send to the Debug adapter?
There is a program called OpenOCD. OpenOCD is a software abstraction of the JTAG protocol. This software program consumes high-level debug commands and outputs JTAG-level commands through the USB port.
From there, the drivers found in the debug adapter convert those USB-wrapped-JTAG-electrical signals into a 4-split output as shown below :
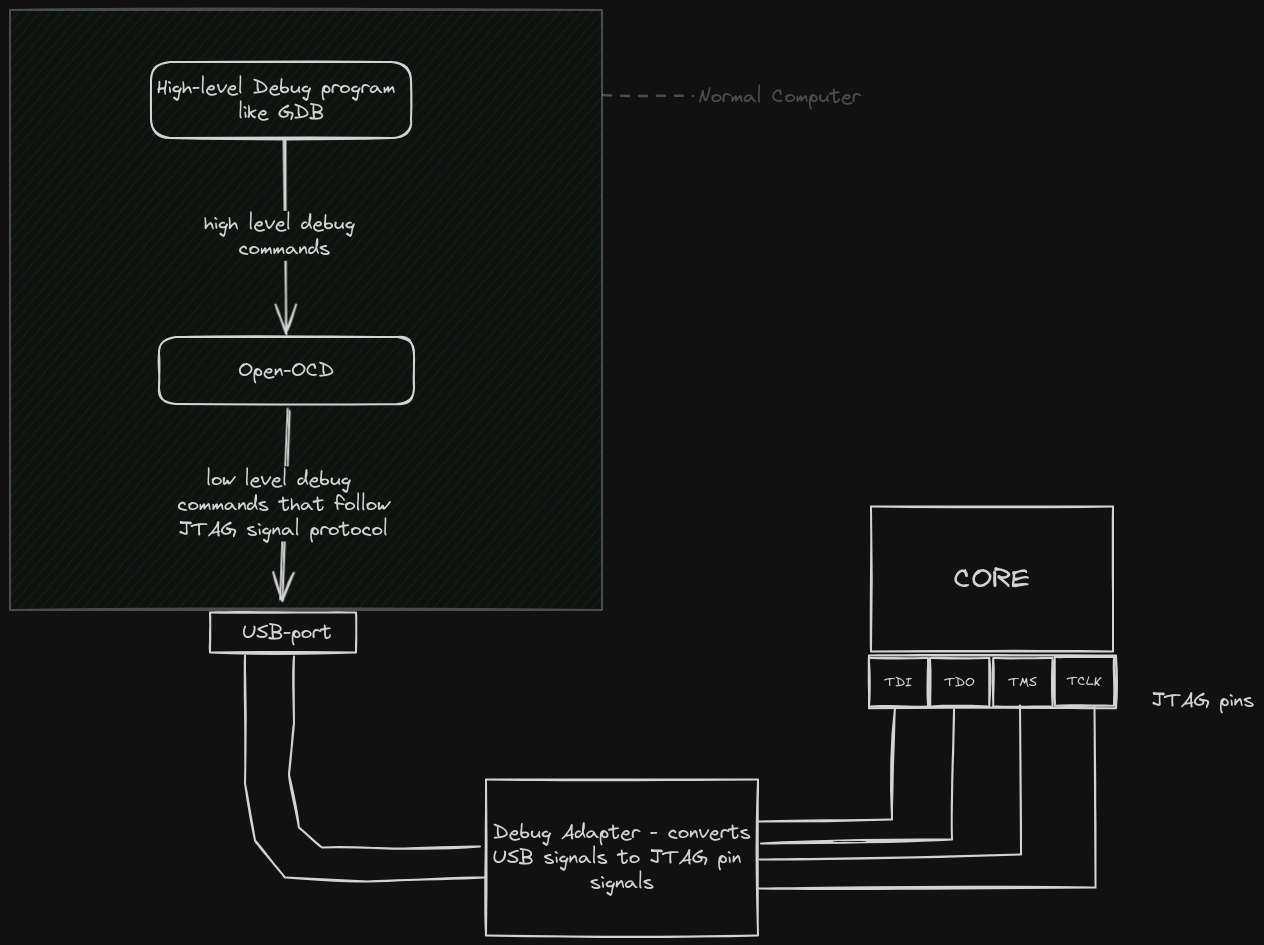
There are many alternatives to OpenOCD... eg Probe-rs and SJLink. OpenOCD was used here just because it is a popular and battle-tested software. So whenever we mention OpenOCD, we are indirectly referring to all the JTAG-protocol software implementations; it is inaccurate but convenient.
Just to clarify, the high level commands that get consumed by OpenOCD do not necessarily have to come from the GDB debugger, they can come from any software that can interface with the API. For example 'flashing programs' and 'Monitoring programs' can also apply here... even well interfaced bash scripts are allowed!
GDB and its alternatives
GDB (GNU Debugger) is a debugging software that has a well defined debugging protocol. There are many other debugging software and corresponding protocols... but we'll stick to GDB because it is has great support, well documented and it has many functionalities. It is battle-tested.
There are three modules of the GDB that are worth noting here :
- The GDB main application (mostly a CLI, but there are GUI implementions too)
- The gdb server
- The gdb stub
The GDB CLI is the core application, the engine. It is interactive and complete.
The gdb server is a proxy between GDB CLI and other applications. Its main roles are :
- Listening & Receiving data/instructions from the GDB CLI
- Listening & Receiving data/instructions from the application that has been interfaced to the GDB CLI
- Passing on received data to the opposite end of the channel.
The gdb stub the gdb stub has two meanings depending on the context. And before we define the meanings, we'll take a detour to understand a tiny part of how a debugger works.
The Detour: How a debugger works
Suppose you are debugging program x on your linux machine... the debub program and program x will run as two seperate processes.
Debugging Information:
When you compile a program with debugging information enabled, the compiler includes additional metadata in the executable binary. This metadata provides GDB with information about the source code, such as variable names, line numbers, function names, and the layout of the program's memory.
Launching the Program:
To debug a program with GDB, you typically start GDB and specify the executable binary of the program as an argument.
GDB loads the executable binary into memory (RAM) and prepares it for debugging. It also reads the debugging information embedded in the binary to understand the structure of the program.
Injecting extra code
When you set debugging breakpoints, what GDB actually does is to insert 'control code' in the process x's RAM text section. Same case to the continue gdb instruction.
During execution, the program's code resides in memory, where it can be modified by the debugger for debugging purposes. This modification is temporary and does not alter the original program file on disk.
When GDB inserts a breakpoint or other debugging instruction, it's modifying the program's code in memory, not the original source code file. This modification allows the debugger to interrupt the program's execution at specific points and provide debugging information to the user without permanently altering the program itself.
Back from the Detour: Defining gdb stub
In the normal debugging context (i.e in a non-embedded environment), the word gdb stub means 'a file that contains the implementations of the control code that usually gets injected by the debugger into the process' memory.
You can learn more about this from the official gdb docs on stubs
In the embedded context, the gdb stub is a piece of firmware that implements the 'control code' that gets inserted in the process' memory. It also contains an implementation of code that allows it to communicate to the gdb server. This GDB stub is usually found on the target machine or the debub probe.
GDB stubs are commonly used in embedded systems for facilitating communication between the target device and the debugger.
Probing Pracs
These pracs will take you through the process of ...
- Configuring the interconnection between the host machine and the target board using udev
- Configuring gdb-to-openOCD-to-chip for the sake of flashing and debugging.
- Setting up defmt and RTT crate for chip monitoring and logging.
- Setting up a no-std testing framework
At the moment, this chapter is under development.
So in the meantime, we will take a shortcut and use the esp-based tools that abstract away all the intricacies of manually setting things up.
Manually setting things up is a good way to learn, but we will take a curve just this one time.
Udev
Reference tutorial : https://opensource.com/article/18/11/udev
Udev stands for User-Device manager.
It is one of linux's subsystems. You can find the other subsystems in the root folder '/sys'.
Udev is the Linux subsystem that supplies your computer with device events.
When you plug in a device to your linux pc...
- The device gets detected by some of udev submodules.
- The device gets abstracted as a file stored in the
/devroot directory. - Udev starts and continues to act as a message proxy between the kernel and device.
- Udev continuously listens and detects events induced by the external device and relays this info to the kernel.
- The kernel on the other hand, returns action responses to udev. Udev then invokes the necessary action given by the kernel responses.
The above description is somehow inaccurate and is given to provide a high-level overview of what happens. To read on the exact order and definitions of things, consult official udev docs.
You can also read the offline docs by running the following cmd command :
man udev
Listing attached devices
The process of detecting and abstracting attached devices as files in the /dev directory happens automatically.
To view attached devices, you can browse through the /dev directory OR use the following cmd commands :
lsusb # List all the devices that have been attached to the USB-controllers
lsblk # List all block devives
lscpu # List all CPUs
lspci # Lists all PCI devices
Reading the results from the cmd commands
Here is an example of a reading :
> lsusb
Bus 001 Device 002: ID 8087:8001 Intel Corp. Integrated Hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 003 Device 002: ID 0424:5534 Microchip Technology, Inc. (formerly SMSC) Hub
Bus 003 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 002 Device 004: ID 05c8:0374 Cheng Uei Precision Industry Co., Ltd (Foxlink) HP EliteBook integrated HD Webcam
Bus 002 Device 003: ID 8087:0a2a Intel Corp. Bluetooth wireless interface
Bus 002 Device 005: ID 0461:4d22 Primax Electronics, Ltd USB Optical Mouse
Bus 002 Device 002: ID 0424:2134 Microchip Technology, Inc. (formerly SMSC) Hub
Bus 002 Device 038: ID 04e8:6860 Samsung Electronics Co., Ltd Galaxy A5 (MTP)
Bus 002 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
The above output depicts that...
- There are at least three USB controllers that have been attached to the BUS. This phenomenon has been denoted by the term BUS [1 - 3] in the above output. Note that a USB-port is not synonymous to USB-controller. A usb controller acts as an interface between the BUS and the USB-hub. The USB-hub contains multiple usb-ports. The usb-ports can be either virtual or physical.
- The
Primax Electronics, Ltd USB Optical Mousehas a device ID of4d22 - The
Primax Electronics, Ltd USB Optical Mousehas a Vendor ID of0461 - The
Primax Electronics, Ltd USB Optical Mousehas been attached USB-port 005 that has association with the second USB-controller - The file that abstracts
Primax Electronics, Ltd USB Optical Mouseis/dev/bus/usb/002/005.
Udev's Real-time monitoring of device-events
With the udevadm monitor command, you can tap into udev in real time and see what it sees when you plug in different devices. Become root and try it.
> sudo -i
> udevadm monitor
The monitor function prints received events for:
- UDEV: the event udev sends out after rule processing
- KERNEL: the kernel uevent
With udevadm monitor running, plug in a thumb drive and watch as all kinds of information is spewed out onto your screen. Notice that the type of event is an ADD event. That's a good way to identify what type of event you want.
Udev's info snooping
You can view the info for a particular device by using the command : udevadm info [OPTIONS] [DEVPATH|FILE].
For example :
# suppose the lsusb command had the folowing output...
# Bus 002 Device 005: ID 0461:4d22 Primax Electronics, Ltd USB Optical Mouse
# Then you would get info about the mouse by...
udevadm info /dev/bus/usb/002/005
Udev scripts
You can write scripts for udev. For example, you may automatically make your flash-drive trigger the execution of a bash script whenever it gets plugged in a specific usb-port.
In normal scripting/programming, you usually identify an object using something like a variable name. However, in udev scripting, you identify devices based on a set of attributes. The more specific the atributes, the more you narrow your reference to a specific device.
Here is a rough format of an instruction :
# This is an exerpt from a udev script
# The following statement means ....
# Whenever a USB device gets ADDed (plugged-in), the 'thumb' script gets ran
SUBSYSTEM=="usb", DRIVER=="usb", ACTION=="add", RUN+="/usr/local/bin/thumb
# But this rule is more specific... it does not specify just a usb device,
# it specifies the product ID and vendor ID of the device
SUBSYSTEM=="usb", DRIVER=="usb", ATTR{idProduct}=="4d22", ATTR{idVendor}=="0461", ACTION=="add", RUN+="/usr/local/bin/thumb_for_mouse
To find the specific attributes of a device and all of its parents, use the command below :
udevadm info -a /dev/bus/usb/002/005
Udev fetches its scripts from /etc/udev/rules.d/.
The script files end with the a .rules extension.
The script files usually begin with a number to show the order in which the scripts get parsed by udev. For example 80-usb-script.rules will get executed before 81-usb-extra-script.rules.
So why were we learning about Udev?
Well, two reasons...
- It's essential knowledge, especially if you'll be handling devices using the linux kernel.
- We will need to interact with the device files. The problem is that the device files are only writable by
root. So we need to make the files that we need accessible to our normal development account.
Pracs
- Attach your Esp32c3 to your computer using a usb cable.
- You will notice that 2 new files get generated under the
/devdirectory. One under tty (eg ttyACM0) and one under/dev/bus. Figure out where and why. These 2 files are there to abstract your device and the USB connection. - Write a script to make these two files accessible to your linux account.
Done!!
Flashing
In embedded development, "flashing" typically refers to the process of writing or programming the firmware or software onto a microcontroller or other embedded system's non-volatile memory. This non-volatile memory can be flash memory, EEPROM (Electrically Erasable Programmable Read-Only Memory), or similar types of memory that retain data even when power is removed.
We will use the esp-flash tool. A tool purposefully built to flash programs into esp boards like our very own Esp32c3.
We could have used other tools like OpenOCD and Probe-rs because they are more generic than espflash. Once you learn them, you can tweak them for different platforms. Espflash is specialized, readers are advised to learn other tools in order to have a holisti growth.
We will use espflash in order to escape the trouble of writing our own configs and flashing algorithm.
The honors of flashing... finally
The esp-rs team did a good job with their docs. Go through the flashing page and do the honors.
Monitoring and Logging
yyyer
draft_1
This page elaborates on the logging architecture.
Typical logging architecture
So how does logging happen? How is the log data encoded? How is the data transmitted? How does the host machine receive and display the log data?
Here is a rough architecture....
Well... there's a lot to unpack here.
Explanations Based on the Image above
Our aim is to :
- Allow the programmer to embed logging 'print' statements in the code
- Make the no-std program have the ability to pass on those log statements to the Serial output of the target chip
- Make the host CPU receive those log statements and display them.
- (optional) provide an interactive CLI app to help the end-user to engage with the data in an interactive manner.
Pre-runtime flow of events
The programmer embeds log_print macros in their code where necessary. And then they compile it.
For example :
#![allow(unused)] fn main() { // no_std module fn _start () { // bla bla bla log::info!("program has finished bla-bla-ing"); if some_variable == true { // ble ble ble log::warn!("program has done ble-ble-ble"); } else { // bli bli bli log::error!("program just did bli-bli-bli, that's an error, deal with it"); } } }
During the compilation process, the compiler expands the log_macros seen above in accordance to the log_crate that the programmer is using. So a line like log::info!("program has finished bla-bla-ing"); will expand to something like :
#![allow(unused)] fn main() { // code block filled with pseudo-code { // this code cotains instructions that can indirectly manipulate UART registers // It could even be written in assembly, if you want finer control over how the log-info gets to be passed. let uart_instance = acquire_uart(); uart_instance.uart_write_string ("program has finished bla-bla-ing"); uart_instance.flush(); } }
Point being, the log macros expand into code that can interact with the serial outout of the SoC. In this case, the macros expand to code that can interact with the UART.
During that same compilation process, the indices of the interned strings get embued as part of the debug section in the final object file.
So what are interned strings?.
Well... the micro-controller has limited memory. We would not like to burden it with the responsibility of storing log_strings. We would not like to make the log_strings part of the binary file that gets loaded onto the MCUs memory.
So people found a way to compress the strings. This string compression consists of building a table of string literals, like "program has finished bla-bla-ing" or "The answer is {:?}", at compile time. At runtime, this table is made accessible for the host machine to view. On the other hand, the target machine sends indices instead of complete strings.
So instead of storing complete strings in the MCU's memory, we store them in the host's memory. The MCU only stores string indices (string IDs).
On top of sparing the MCUs memory, this technique increases the logging throughput; the MCU can use a single byte to convey an entire 256-byte string.
In summary, Interned strings are the strings that get indexed in the compression process. Log crates usually store them as debug info in the program's object file.
Runtime flow of events
These are the events that happen during the actual logging.
Here are the assumption is that...
- The program is already running in the MCU
- The debug info has been loaded in the host machine.
- There is a decoder, and printer installed on the host machine.
From the above image...
The log_print macros found in the no_std app get executed by the processor of the SoC.
And since those code snippets contain code that manipulates the UART driver, they get used to transmit the indices of the interned strings to the UART.
The data that gets transferred to the UART is unformatted .
With the assumption that the HOST machine has USB ports only, we are forced to use a UART-to-USB integrated circuit to convert the UART signals into USB-compatible signals.
The SoC's USB transfers the data to the host's serial input(another USB).
The decoder
The decoder is a program that decodes the indices in the received data.
The log data received from the SoC contains indices that reference actual strings found in the debug section of the target object file.
The decoder's work is to fetche the respective interned strings from the debug section and resolve/expand all the indices.
The decoder then outputs the complete AND unformatted logs.
The Printer
The printer is a program that ...
- Takes in unformatted logs and formmats them
- Interacts with the host's console in order to output the logs in a presentable way (tables, buttons, percentages... basically a UI)
Both the decoder and the printer can be custom-made crates or established third-party software. The choice is up to you.
Unformatted data?
What is formatting in general?
Formatting is the process of converting raw data into another form that is presentable.
For example, you can format a struct to be a string
#![allow(unused)] fn main() { // this is pseudo, no syntax rules have been observed struct Time { year : 2024, month : "January", date : ... hr... min... } fn format ( input: &Time) -> String{ // outputs a string like ... // "25th January 2024 at 0800hrs" } }
So you can say, "the struct Time can be formatted into a string.
What is formatting in the logging context?
Formatting in the logging context involves ...
- Converting raw binary data into strings.
- Implementing the format styles of respective data.
For example :
# Here is a conversion of raw data into strings
`255u8` gets converted into into "255"
# Here is an implementtion of formatting styles
log::info!("{=u8:#x}", 42); will be formatted to the string "0x2a"
log::info!("{=u8:b}", 42); will be formatted to the string "101010"
The logging data coming out of the SoC is usually unformatted so as to spare the MCU's processor from having to do the conversion/formatting. All the heavy-lifting is made to be the host's resposibility.
Critical Section
What is a critical section?
I'd rather give you two definitions or the sake of clarity ...
-
A critical section refers to code that accesses shared resources (e.g., global variables, hardware registers) that must be protected from concurrent access by multiple execution contexts (such as threads or cores) to avoid race conditions.
-
A critical section is a section of code that contains statements that require atomicity and isolation to prevent undefine behaviour caused by data-races. Most of the time, these activities involve modifying shared resources. eg a global mutable variable or a peripheral-registers.
The critical-section crate
The critical-section crate provides a critical-section management API above arbitrary environments.
It is up to the environment creators to provide implementations of the functions listed in the API.
For example
The critical-section crate in Rust is designed for managing critical sections. It provides a universal API for creating, acquiring and releasing critical sections across different environments. It ensures that only one execution-context(not necesarily a thread) can access the critical section at a time, usually by disabling interrupts in embedded systems or acquiring a lock in multi-threaded applications.
You can read the crates docs for better understanding.
Types of Critical Section implementations
-
If you are in a single-core bare metal environment, you can execute the critical section in isolation by disabling all interrupts coming from peripherals.
-
If you are in a multi-core bare metal environment, you can execute a critical section in isolation by...
- disabling all interrupts coming to the subject core AND...
- Putting all the other cores on sleep (or a spinlock) whenever they want to execute a critical section that may affect the critical section that is currently getting exeuted. In short, no two cores should execute conflicting critical sections in parallel. Cores can however execute non-conflicting critical sections.
-
For a bare metal environment where you have limited memory control, eg (if you are in priviledged mode instead of machine mode in riscv) - you can make syscalls that invoke machine mode functions mentioned above.(ie the above 2 paragraphs you just read)
-
For hosted environments, you can either invoke library functions provided OR use the synchronization primitives provided(eg Mutex, SpinLock, Semaphores). Hosted environments are setups where a kernel or management runtime is avalilable.
An internal look at the critical-section crate
Get the source code of critical-setion crate. (this book used version 1.1.3)
I hold the bias that : "it is not enough to read the docs of a vital crate, you need to understand how it internally works by parsing through the code yourself" - this bias is very important especially for a firmware/driver dev who needs to control low-level aspects of their code. You need total/major control over your code.
And it is our luck that critical-section has no dependencies and it has less than 700 lines of code. Parsing it would be somehow easy.
Cargo.toml
When you look at the cargo file, you note that the crate has a couple of features named using the form restore-state-[type_name] eg restore-state-bool, restore-state-u32... as seen below :
[features]
restore-state-bool = []
restore-state- none = []
restore-state-u16 = []
restore-state-u32 = []
restore-state-u64 = []
restore-state-u8 = []
restore-state-usize = []
std = ["restore-state-bool"]
So, what is this restore-state-* thing?
To find out the answer, we move on to the lib.rs, maybe we'll find answers there....
Aaah... there's so much happening in lib.rs, I don't get it; lets just visit mutex.rs first since it is one of lib.rs building mods. Bottom up understanding.
mutex.rs depends on the critical_section struct.
#![allow(unused)] fn main() { #[derive(Clone, Copy, Debug)] pub struct CriticalSection<'cs> { _private: PhantomData<&'cs ()>, } }
The designers of the crate hoped that : "if a thread wants to execute a critical section, it would first instantiate a critical_section struct that will be dropped by the thread once it has finished executing the critical section"
This means that we have to find how they ensured that...
- Each independent critical section got a unique
critical_sectionstruct instance. eg CriticalSection A is tied tocritical_section_struct_Awhile CriticalSection B is tied tocritical_section_struct_B - The number of instances of a
critical_sectionstruct that exist must not exceed one.
A question for you... "Why use phantom data in the struct? As far as we can tell, the phantom data was unnecessary"
(undone chapter)
Examples
Real-world Driver Development Examples
- Redox Examples
- Linux driver examples.
- keyboard driver
Notable Crates
For bare metal programming
- heapless
- critical-section
- portable-atomic
- bit-field, bitfield
- bit-flags
- embedded-hal
- embedded-dma : This library provides the ReadBuffer and WriteBuffer unsafe traits to be used as bounds to buffers types used in DMA operations.
- fugi : time crate for embedded systems
- nb : Minimal and reusable non-blocking I/O layer
- riscv
- riscv-rt
- volatile-register
- vcell : Just like Cell but with volatile read / write operations
- svd2rust
- svd2utra
- rtic
- tock-registers
- drone-svd
- loom
- crossbeam-utils : Utilities for concurrent programming
- serde
- sptr: This library provides a stable polyfill for Rust's [Strict Provenance] experimen
Utility-like
- svd2rust + form + rustfmt
- defmt : A highly efficient logging framework that targets resource-constrained devices, like microcontrollers. Check out the defmt book at https://defmt.ferrous-systems.com for more information about how to use it.
- embassy crates
- probe crates
- clap
- ratatui
- serde
Panicking
- panic-abort. A panic causes the abort instruction to be executed.
- panic-halt. A panic causes the program, or the current thread, to halt by entering an infinite loop.
- panic-itm. The panicking message is logged using the ITM, an ARM Cortex-M specific peripheral.
- panic-semihosting. The panicking message is logged to the host using the semihosting technique.
- more here : https://crates.io/keywords/panic-handler
more tertiary for now
- cfg-if : A macro for defining #[cfg] if-else statements.
- core::mem
- core::ptr
- core::alloc // Thiis is different from the Alloc crate
- core::fmt
- core::panic
- core::cell
- core::ffi
- core::io
- core::error
- The rest of the modules are somehow secondary
Why Embedded Rust
Memory Safety:
Rust's ownership system and borrow checker ensure memory safety without the need for a garbage collector. This helps prevent common issues like null pointer dereferences, buffer overflows, and data races.
Concurrency and Parallelism:
Advantage: Rust provides ownership-based concurrency control, allowing developers to write concurrent code without the risk of data races. The language's emphasis on zero-cost abstractions enables efficient parallelism.
Nice integration with C and C++... and their respective tools
- Rust has a robust FFI that allows seamless integration with C and C++ code.
- Cargo integrates well with tools that are popular in the embedded world, so a C developer needs not learn ALL NEW things. For example the default toolchain components are extended LLVM or GNU components. You can integrate C library and build tools in a seamless manner in your project.
Ergonomics
- Tools are considerably documented.
- Helpful community
- many helpful tools & crates... especially the compiler itself.
Naive but somehow true perspective : Rust enables you to write complex software (even as a junior), your implementation is not 100% dependent on your experience level.
The Rust Toolchain
This is not a topic that you must read.
It explains how cross-compilation happens in Rust. We discuss LLVM tools and their comparison to GNU tools. We discuss different Rust-compiler back-ends and how you can tweak them.
undone : finish up this chapter
Explanations on buzzwords
This chapter contains small-small explanations on buzzwords that may have been used in this book.
Read the sub-chapters as an intro and then read the tagged references to dive deeper on the covered subjects.
Firmware versus Drivers
Like we said, definitions in tech are somehow subjective.
Firmware
We had earlier defined Firmware as... >Firmware is software that majorly controls the hardware. It typically gets stored in the ROM of the hardware
There are many things that control hardware, even your browser controls hardware. So does that make it firmware? The kernel controls hardware, does that make it firmware? - No.
If I decide to store a picture of an Anime-cat-girl in the ROM of a device, does that make it firmware? If I decide to store a small OS in the ROM, does it make it firmware? - No.
What if I store the code used to control hardware in a seperate hard-disk instead of the ROM? Does that make the code lose its status of being called firmware? - NO.
In the end, it is up to you, to decide if you want to call your code firmware.
If you write code that directly interacts with the circuitry of a device, then you have written firmware.
Drivers
We had earlier defined drivers as ...
A Driver is software that controls the hardware AND provides a higher level interface for something like a kernel or a runtime.
Drivers and hardware control
A driver controls hardware, but it is not as intimate to the machine as firmware.
This is because the firmware is made specifically for the external device's motherboard, its code references specific registers within the external device.
The driver on the other hand is more generic, it is not really made for the specific external device's motherboard, its code mostly references the registers of the host computer and the devices external registers. The driver rarely references the internal registers found in the external device.
Drivers even use firmware as dependencies.
The main point here is that the driver is a higher level of abstraction that is dependent on firmware as its building block.
So in as much as it controls hardware, it is not as intimate as how the firmware does it.
Here is an example situation, A hard-disk driver may initiate a read-operation that will result in the spinning of disks within the external hard-disk. But its the firmware that will control how those disks spin.
The thin line
What if I write a driver that references the internal registers of an external device, does that make my driver to also be Firmware?
What if I create firmware that exposes a mature & generic API that can be referenced to by the Kernel/Runtime code. Does it make that firmware to also be a driver?
I hope that this section has caused more confusion.
Thank you for listening to my ted-talk and Bye.
C standard libraries
There are many C-libraries.
- glibc
- musl
- uClibc
- newlib
- MinGW-w64
Newlib
Newlib is a lightweight and efficient C library primarily designed for embedded systems and other resource-constrained environments. It provides standard C library functionality, including input/output, string manipulation, memory management, and more, while prioritizing small size and minimal overhead.
Although it aims to offer POSIX compatibility, Newlib does not implement the full range of POSIX functions found in larger libraries like glibc. Suitable for bare-metal environments, Newlib serves as a practical choice for projects where conserving resources is paramount and where comprehensive POSIX compliance is not a strict requirement.
glibc (GNU C Library):
glibc is the standard C library for the GNU operating system and most Linux distributions.
It provides comprehensive POSIX compatibility and a wide range of features, but it is relatively large and may not be suitable for embedded systems with limited resources.
musl libc:
musl is a lightweight, fast, and efficient C library that aims to provide POSIX compatibility with minimal overhead. It is designed to be small and suitable for embedded systems and other resource-constrained environments.
If you intend to primarily write your code in Rust and want to leverage the Rust ecosystem, using the Generic ELF/Newlib toolchain might not be the most desirable option. Here's why:
Compatibility: The Generic ELF/Newlib toolchain is primarily tailored for C development, particularly in embedded systems or bare-metal environments. While Rust can interoperate with C code, using Newlib might introduce additional complexity when working with Rust code.
Standard Library: Rust provides its standard library (std), which is designed to work across different platforms and environments. By default, Rust code targets libstd, which provides a rich set of functionality beyond what Newlib offers. Using the Generic ELF/Newlib toolchain might limit your ability to leverage Rust's standard library and ecosystem.
Community Support: Rust has a vibrant community and ecosystem, with many libraries and tools developed specifically for Rust. Using the Generic ELF/Newlib toolchain might limit your access to these resources, as they are often designed to work with Rust's standard library (std) rather than Newlib.
Maintenance: While it's possible to use Rust with the Generic ELF/Newlib toolchain, maintaining Rust code alongside C code compiled with Newlib might introduce challenges, especially if you're not already familiar with both languages and their respective toolchains.
Instead, if you intend to write mostly in Rust, consider using toolchains and libraries that are specifically designed for Rust development in embedded systems or bare-metal environments. For example, you could use toolchains targeting libcore or libraries like cortex-m, embedded-hal, or vendor-specific hal crates, which provide idiomatic Rust interfaces for interacting with hardware and low-level system functionality. These options are more aligned with Rust's design principles and ecosystem and might provide a smoother development experience for Rust-centric projects.
Runtime
What is a C runtime? What is a Rust runtime? What is a runtime?
100 Meanings
Well, the word runtime is a dense word, with multiple meanings that vary with context. Here are some of the definitions :
Meaning 1 :
Runtime refers to the duration of time consumed when a program was executing.
For example, if you played a videogame for 12 hours, you could say that that videogame had a 12-hour runtime.
Meaning 2 :
Runtime refers to a piece of software that continuously tends to the needs of another running program.
For example :
-
In the case of programs written with languages with garbage-collection, you could say that those programs depend on a runtime-software to continuously collect the dead variables as a background service. In this case, the garbage-collector is part of the runtime.
-
In the case of Intepreted languages, you could say that the intepreter itself is the runtime service. This is because the intepreter needs to continuously compile and execute the program as it runs.
Meaning 3 :
Programs usually don't start getting executed just like that. There has to be code that makes the CPU to point to and fetch the right lines of code, make sure that there is enough stack space, make sure that some CPU registers have the expected default values...
Point is, there is some code that gets executed before the actual program ie. Init code AND control code.
In this context, Runtime means init-code. Runtime means control code.
Some parts of the runtime code get executed once while other parts get executed continuously & dynamically.
For example, control functions like overlay control,stack overflow protection and Exception Handling get executed continuously & dynamically. Functions like program-stack initilization get executed only once at the start of the program.
Some compilers can be set to statically insert such control code in every place they are needed at compile time. Other compilers allow you to reference them dynamically.
If you are short on space, you can go the dynamic path.
If you are not short on space and you require performance, it's better to go the static path.
The C Runtime
Hopefully, you've read this intro to runtimes.
The C runtime follows the third meaning. ie The C runtime is the startup code that gets executed in preparation for the call to the main function.
Unlike the JAVA runtime and JS runtime, the C runtime is not an application that runs independent of the user-program. The C runtime is a set of library files that get statically compiled together with your C code. C runtime is not an independent application, it is a dependency that gets linked and compiled together with the program that you are writing.
This C runtime is usually nick-named CRT-0 and is typically written in assembly code.
Functions of the C runtime code
There are many variations of the C-runtime.
It is a free-world. It is up to you to decide what your C-runtime does.
However, here are some of the typical functions found in any C-runtime library.
- Loading elf programs from ROM/secondary_memory to RAM.
- Allocating space for the stack and initializing the stack pointer
- Allocating space for a heap (if used)
- Initializing global static variables before the program execution begins. This is achieved by copying values from Flash into variables declared with initial values
- Zero-ing out all uninitialized global variables.
- Clearing uninitialized RAM
- Populating the vector table so the device can properly dispatch exceptions and interrupts.
- Calling the
main()function safely.
Extra and non-vital functions include :
- Setting up overlay control code.
- Setting up Stack protection code.
- Setting up stack unwinding code.
Quite a mouthful ha? So many functions!
Here are resources that will help you understand the C-runtime :
- The C Runtime Environment by microchip.com. This summarizes things in a clean way. Best resource here.
- This c_startup blog by Vijay Kumar B on bravegnu.com takes you through writing a simple Runtime targeting the ARM board. If you have no interest in ARM, you can just skim through the tutorial and get the gist.
- Good old wikipedia.
Examples of C runtimes
You can look at the code found in these repos in order to get a gist of how the internals of a C-runtime look like.
- An implementation in Rust : r0 by rust-embedded group
- An implementation in Assembly + Rust targeting Riscv boards : riscv-rt by rust-embedded group
Later, we will write our own Runtime targeting the Riscv Board that we will be working with
You can always skip the whole process of writing your own runtime and instead use
riscv-rt, but where is the fun in that?
The Rust Runtime
(undone chapter)
Hopefully, you've read this intro to runtimes.
Unlike the JAVA runtime and JS runtime, the Rust runtime is not an application that runs independent of the user-program. The Rust runtime is a set of library files that get statically compiled together with your Rust code. Rust runtime is not an independent application, it is a dependency that gets linked and compiled together with the program that you are writing.
The Rust runtime follows the third meaning. ie The Rust runtime is the startup code that gets executed in preparation for the call to the main function.
Note from the author...call or content-contributions
I do not undertand exactly what the Rust-runtime on unix does.
Here is the source code for the Runtime : link to page
Here is a page that tries to explain what the runtime does : The Rust Reference book: The Rust runtime
I am currently assuming that the functions of the Runtime are...
- Setting up threading and creating a new special thread for 'main'
- Inserting
clean_upcode. This is code that MAY get executed at the end of themainfunction. It clears up memory. - Setting up backtracing functions
- Setting up panicking behavior, especially
panic-unwinding. - Availing Heap handling wrapper functions
- OS-to-process Signal handling
- Stack management (eg no overflows)
- Thread management (eg ensure sharing rules a)
Silver lining
Since the Rust runtime is std-dependent, we are better off spending our time understanding alternative runtimes that ...
- are
no-stdcompliant - implement protection features that may be missing from the C-runtime
Our main focus will now be on riscv-rt, a riscv-runtime built by the embedded-rust team.
link pointing to the chapter covering riscv-rt
(undone: this chapter is wanting)
Riscv Runtime
execution-environment
undone : update this chapter
APIs
What is an API?
Application Programming Interface is a set of rules (diguised as functions), protocols, and tools that allows different software applications to communicate and interact with each other.
It does so by defining the methods and data formats that developers can use to request and exchange information between software components.
So you can say an API is the interface for an application. It contains objects and functions that can be called by other apps.
Here are some examples of different APIs ....
Example 1 (Library API):
The simplest and common type of API is a Library API. Library APIs define the methods, classes, and data structures that developers can use when programming with the library.
For example, If you are trying to write an CLI-app that prints a random number on screen, chances are that you might import and use the rand library/crate. Here is the 'rand' crate's library API documentation:
The [rand] library exposes these functions, these traits and this struct as its API. If you use the rand crate in your app, you can interact with it by bringing these exposed items in the scope of your app.
Example 2 (Kernel API):
Operating System APIs are provided by operating systems to allow applications to interact with system resources such as files, processes, and devices. They provide a way for applications to access low-level functionality without needing to understand the underlying hardware or system architecture.
Here is the Linux Kernel API.
From the page, you can see it exposing datatypes and functions. For example, It exposes the Doubly Linked List and all the methods associated with that doubly-linked-list.
Example 3 (Database APIs):
Database APIs provide a way for applications to interact with databases, allowing them to perform operations such as querying data, inserting records, and updating information.
For example a relational database may expose functions that assist the programmer in creating, modifying and deleting tables.
APIs enable interoperability between different software systems, allowing them to work together seamlessly. They abstract away the complexities of underlying systems and provide a standardized interface that developers can use to build applications.
ABIs
Tbh, the current author is really having a hard time defining what an ABI really is. Contributions are welcome
- What it entails,
- what it doesnt entail,
- why it has what it has,
- which components are affected by the ABI specifications {compiler, linker, language-runtime, processor, loader}
The author is also having a hard time differentiating the different ABI standards and defining their trade-offs in different situations.
So far, the Riscv ABI specs have been helpful.
(undone)
What is an ABI?
An ABI (Application Binary Interface) is a set of specifications defining....
Post runtime specs
- Data representation: How data types are represented in memory, including issues like endianness (byte order), alignment, and padding.
- Object file formats: The structure and layout of object files, which contain compiled code and data before they are linked into an executable.
Runtime specs
- Dynamic linking: How dynamically linked libraries are loaded and resolved at runtime.
- Function calling conventions: How parameters are passed to functions, how return values are returned, and how functions are invoked.
- https://stackoverflow.com/questions/2171177/what-is-an-application-binary-interface-abi
THe ABI defines the :
- Calling conventions
- How parameter are passed
- Object file format
- Executable file format
- stack frame layout
- How types get encoded
- endianness
- lengths
- encode pattern (eg characters use UTF-8)
The C ABI?
C itself as a language standard doesn't define a specific ABI (Application Binary Interface). Instead, the ABI is typically determined by the platform and compiler being used. An ABI defines how functions are called, how parameters are passed, how data is laid out in memory, and other low-level details necessary for binary compatibility between separately compiled modules.
Different compilers and platforms may have their own ABIs. For example:
x86-64 System V ABI: This is the ABI commonly used on many Unix-like operating systems for 64-bit x86 processors. It specifies how parameters are passed, how the stack is managed, how functions are called, etc.
Windows x64 ABI: Microsoft Windows uses its own ABI for 64-bit x86 processors, which differs in certain aspects from the System V ABI.
ARM EABI: The Embedded Application Binary Interface for ARM processors, which defines how code should be compiled and linked for ARM-based systems.
RISC-V ABIs: As discussed earlier, there are several ABIs for RISC-V processors, such as ilp32, lp64, etc.
Riscv ABIs
Messes
- see symbol table and learn to understand it
- see relocation table and learn to understand it
- disassemble a program
- assemble a program
- link a couple of object files into an executable, observe the relocation
- see the undefined reference in object symbol and relocation table. Before and after linking
On using GNU-based toolchains
If you intend to primarily write your code in Rust and want to leverage the Rust ecosystem, using the Generic ELF/Newlib toolchain might not be the most desirable option. Here's why:
Compatibility: The Generic ELF/Newlib toolchain is primarily tailored for C development, particularly in embedded systems or bare-metal environments. While Rust can interoperate with C code, using Newlib might introduce additional complexity when working with Rust code.
Standard Library: Rust provides its standard library (std), which is designed to work across different platforms and environments. By default, Rust code targets libstd, which provides a rich set of functionality beyond what Newlib offers. Using the Generic ELF/Newlib toolchain might limit your ability to leverage Rust's standard library and ecosystem.
Community Support: Rust has a vibrant community and ecosystem, with many libraries and tools developed specifically for Rust. Using the Generic ELF/Newlib toolchain might limit your access to these resources, as they are often designed to work with Rust's standard library (std) rather than Newlib.
Maintenance: While it's possible to use Rust with the Generic ELF/Newlib toolchain, maintaining Rust code alongside C code compiled with Newlib might introduce challenges, especially if you're not already familiar with both languages and their respective toolchains.
Instead, if you intend to write mostly in Rust, consider using toolchains and libraries that are specifically designed for Rust development in embedded systems or bare-metal environments. For example, you could use toolchains targeting libcore or libraries like cortex-m, embedded-hal, or vendor-specific hal crates, which provide idiomatic Rust interfaces for interacting with hardware and low-level system functionality. These options are more aligned with Rust's design principles and ecosystem and might provide a smoother development experience for Rust-centric projects.
Instruction Set Architectures (ISAs)
An ISA specification is a piece of document that elaborates on how a certain processor functions. It does so by explaining the things listed below :
-
Supported Instructions: This refers to the set of operations or commands that a processor can understand and execute. Instructions could include arithmetic operations (addition, subtraction, multiplication, division), logical operations (AND, OR, NOT), control flow operations (branches, jumps, calls), and others specific to the architecture.
-
Data Types: ISA specifies the types of data that can be manipulated by the processor. This might include integer types (such as 8-bit, 16-bit, 32-bit, or 64-bit integers), floating-point types (single precision, double precision), and sometimes vector or SIMD (Single Instruction, Multiple Data) types for parallel processing.
-
Registers: Registers are small, fast storage locations within the processor that hold data temporarily during processing. ISA defines the number of registers, their sizes, and their intended purposes (e.g., general-purpose registers, special-purpose registers for specific tasks like storing the program counter or stack pointer).
-
Hardware Support for Managing Main Memory: ISA specifies how the processor interacts with main memory (RAM). This includes mechanisms for loading and storing data from/to memory, handling memory access permissions, cache management, and mechanisms for memory protection to prevent unauthorized access.
Think of the ISA as a manual for your processor.
There are no rules as to what an ISA should entail, the creator chooses how to write the manual.
If you build a nano-processor that uses DNA-magic, it will be up to you define your own unique manual.
For reference, here are the Riscv ISA specifications
Factors that affect the content and structure of an Object File
undone: update this chapter
How to build runtimes
- Provides the following attributes for the no-std programer :
- #[entry]
- #[exception]
- #[pre_init] to run code before static variables are initialized
- #[interrupt], which allows you to define interrupt handlers. However, since which interrupts are available depends on the microcontroller in use, this attribute should be re-exported and used from a device crate
rustup-target-add
What doe the command below actually do?
rustup target add riscvi32-unknown-none-elf
When you run rustup target add riscvi32-unknown-none-elf, Rustup performs several actions to add the specified target to your Rust toolchain. Let's break down what happens in technical terms:
- Downloads the Target Specification File : Rustup downloads the target specification file for the specified target architecture (riscvi32-unknown-none-elf). These file defines various attributes of the target, such as its architecture, ABI (Application Binary Interface), and features. You can view such a file by running the command below:
# Replace `riscv32i-unknown-none-elf` with a target of your liking
rustc -Z unstable-options --target riscv32i-unknown-none-elf --print target-spec-json
-
Installs Associated Toolchain Components: Rustup installs the necessary components and tools required to compile Rust code for the added target. Some of the components include
-
Linker Script: Rustup may download a default linker script suitable for the target architecture. The linker script defines how the compiled code should be linked together and laid out in memory.
-
Core Library (libcore): For bare metal targets like none, Rustup installs a precompiled core library (libcore) tailored for the target architecture. libcore contains essential language primitives and types required for Rust programs, such as basic types (u8, i32, etc.) and core language features. This library is stripped down compared to the standard library (std) and does not include platform-specific functionality or I/O operations.
-
Any new and necessary LLVM component. eg a new linker flavour
-
-
Updates Rust Toolchain Configuration: Rustup updates the configuration of your Rust toolchain to include the newly added target. This ensures that when you compile Rust code using this toolchain, the compiler knows about the added target and can generate code compatible with it.
Direct Memory Access
communication protocols
The UART is not the only physical communication protocol for serial communication. There are more modern alternatives, for example;
- USB (Universal Serial Bus)
- SPI (Serial Peripheral Interface)
- I2C (Inter-Integrated Circuit)
Look into physical layer protocols like RS-232, RS-422, RS-485.
What to look out for at the OSI physical layer protocol:
- Pin number
- Pin configuration (information associated with each pin)
- Transmission length
- Error Handling techniques (parity-checking, differentials_btwn_voltages, ...)
- Signal levels and associated power usage of the devices
- Transfer speeds
- Noise Immunity
- Configuration process and its complexity (auto-config support, chances of misconfiguration)
- Support of a limited number of connected devices (ep point-point vs multipoint vs broadcast-support)
- Ergonomic :Plug-and-play functionality and widespread support.
- Consume the pointer pointing to a peripheral. Make sure ONLY one &mut T points to that peripheral. No other mutable reference should be used to reference that peripheral.
/// Systick is a peripheral based on the memory map below /// | Offset | Name | Description | Width | /// |--------|-------------|-----------------------------|--------| /// | 0x00 | SYST_CSR | Control and Status Register | 32 bits| /// | 0x04 | SYST_RVR | Reload Value Register | 32 bits| /// | 0x08 | SYST_CVR | Current Value Register | 32 bits| /// | 0x0C | SYST_CALIB | Calibration Value Register | 32 bits| /// /// /// The base register of Systick is at address 0xE000_E010 #[repr(C)] struct SysTick{ csr: u32, rvr: u32, cvr: u32, calib: u32 } fn main(){ // Bad Example : the pointer to peripheral is not deleted { let sys_tick_instance_ptr = 0x200000 as *mut SysTick; let sys_tick_ref = unsafe { sys_tick_instance_ptr as &mut SysTick }; *sys_tick_instance_ptr = 67; // we want to avoid untracked mutations like this line. // It is better to stick to using references over pointers. // Avoiding pointers has the downside that offset-calculations will be unavailable... But... // But you can solve that by creating better struct-abstractions over the offset-memory-region } // end of bad example // Good example : Raw pointer is immediately deleated { let sys_tick_instance_ptr = 0x200000 as *mut SysTick; let sys_tick_ref = unsafe {sys_tick_instance_ptr.as_mut()}; // as_mut() consumes the pointer as a value *sys_tick_instance_ptr = 67; // this will throw a compilation error. You are restricted to just using the sys_tick_ref. } // end of good example }
- Make sure the data behind pointers are Non-Copy. If they are Copy-able, make sure you NEVER implicitly try to take ownership. This is better explained with the code below.
#![allow(unused)] fn main() { // Ownership primer loading.... // this is a custom i32 that does not implement Copy trait. It will become relevant in a few lines to come struct NoCopyi32{ data: i32 } // every time you run a `let` statement, a new address in the stack must be instatiated. // eg : 2 different addresses will be displayed in the 2 printlns! below. let x = 10; println!("address of x: {}", ptr::addr_of_mut!()); let x = 20; println!("new address of x: {}", ptr::addr_of_mut!()); // Let's look at another situation where both x and y hold values that implement the Copy trait let x = 30; // new stack address gets named `x`, 30 gets stored under that address let y = x; // new stack adddress gets named `y`, // rust-runtime copies the value in `x` and pastes it in `y`. // Rust does not Invalidate `x` because `x` and `y` are holding values without Copy trait println!("{}", x) // compiler does not complain about this line. println!("address of y: {} is different from address of x: {}. Both x & y are valid", ptr::addr_of!(y), ptr::addr_of!(x)); // NOTE this. // the above line will be called `LINE_A` // Let's look at another situation where both x and y hold values that DON'T implement the Copy trait let x = NoCopyi32{data: 40}; // new stack address gets named `x`, 40 gets stored under that address let x_addr = ptr::addr_of!(x); let y = x; // new stack adddress gets named `y`, // rust-runtime copies the value in `x` and pastes it in `y`. // Rust INVALIDATES `x` because `x` and `y` are holding values with Copy trait print!("{} \n", x) // compiler COMPLAINS about this line. println!("address of y: {} is different from address of x: {}. But x is no-longer valid", ptr::addr_of!(y), x_addr); // NOTE this. // the above line will be called `LINE_B` // NOW to pointers!!! // Peripherals have definite addresses. To manipulate a peripheral, you must manipulate a specific address ONLY. // // Let us look at situation where Copyable values make us deviate from our goal of ONLY affecting a SPECIFIC address. let reg_address = 0x20000; let reg_ptr_1 = reg_address as *mut i32; // i32 implements Copy trait let mut reg_value = unsafe { *reg_ptr_1 } // This line tries to take ownership of value behind pointer // the let statement creates a new address (eg 0x80000) in the stack and calls that address `reg_value` // the rust-runtime copies the value contained in the address `0x20000` and pastes it in the address of `reg_value` // Rust does not invalidate reg_ptr_1 // so when you run the line below, you are not modifying `0x20000`, you are modifying the new address(0x80000). // in-short, because of the implicit copy, you are no longer modifying the peripheral address reg_value = 10; println!("address of reg_value: {} is different from address of peripheral: {}.", ptr::addr_of!(reg_value), ); // Possible solutions: // 1. avoid using Copyable values behind pointers AND use references to modify register value(Best solution IMO) // 2. If you can't help but use Copyable values eg usize, then never try to take ownership and instead use only one mutable reference to access the registers }
-
Err on the side of using
as_refandas_mutinstead of manually referencing the value behind a pointer.as_refandas_mutmake sure that you are referencing non-null and aligned values. -
Reduce the number of unsafe accesses.
-
Make all accesses to the register to be volatile... unless volatility is not a problem
-
Preserve access permissions eg if a register is meant to be read-only, provide a read-only interface for on-top of the abstraction that you will create. (hint: use volatile-register crate)
-
Use global singletons to ensure that Mutable borrows occur only once. Treat hardware as data. You can use libraries such as rtic to help co-ordiate peripheral sharing among different programs (immitate a kernel)
svd2rust further explanations
This is a cheap summary from the svd2rust docs.
From the docs :
Generating an ISA-specific PAC crate
svd2rust can generate PAC crates that are either ISA-specific OR ISA-agnostic.
Currently supported ISAs are: Riscv, Cortex-m, MSP430, Xtensa and LX6.
What is an ISA-specific PAC crate?
This is a PAC crate that... (undone)
To generate a PAC crate for a particular supported micro-controller, you can run one of the following commands. (undone)
Generating an ISA-agnostic PAC crate
To generate a PAC crate for a custom micro-controller, you can ... (undone)
Atomics
(undone)
- flag : --atomics (Generate atomic register modification API)
- flag : --atomics-feature
(add feature gating for atomic register modification API)
Enumerated field values
(undone)
Logging and debugging
(undone)
- flag: impl-defmt
- log <log_level> Choose which messages to log (overrides RUST_LOG) [possible values: off, error, warn, info, debug, trace]
- flag: impl-debug
- flag: impl-debug-feature
Documenting
- flag: --html-url
- arranging files
Combining configs
- flag: --config <TOML_FILE>
File Organization
- generic.rs
- build.rs, build script that places device.x somewhere the linker can find
- device.x, linker script that weakly aliases all the interrupt handlers to the default exception handler (DefaultHandler)
- lib.rs
- group
- rustfmt and form
Runtime feature
What the runtime feature does:
- It Imports the error handlers defined in files found in the rustc search path and includes them as part of the crate's namespace. It does this through an extern import like so...
#![allow(unused)] fn main() { #[cfg(feature = "rt")] extern "C" { fn WIFI_MAC(); fn WIFI_MAC_NMI(); fn WIFI_PWR(); fn WIFI_BB(); fn BT_MAC(); fn BT_BB(); fn BT_BB_NMI(); fn RWBT(); fn RWBLE(); fn RWBT_NMI(); fn RWBLE_NMI(); // other error handler functions have been snipped .... } }
The names of these event handlers have beed declared in the device.x file.
If you look at the device.x file, you will notice that the Interrupt_symbols have been weakly defined using the PROVIDE linker keyword. The symbols have been given the value ``DefaultHandler`
2. After importing those error handlers into the namespace, it encloses them in a static public vector-array (function array) for the sole purpose of making it easy for the linker to locate the Interrupt symbols.
This is achieved through the same old trick of demangling symbols and making them globally accessible like this...
#![allow(unused)] fn main() { #[repr(C)] pub union Vector { pub _handler: unsafe extern "C" fn(), pub _reserved: usize, } #[cfg(feature = "rt")] #[doc(hidden)] #[no_mangle] pub static __EXTERNAL_INTERRUPTS: [Vector; 62] = [ Vector { _handler: WIFI_MAC }, Vector { _handler: WIFI_MAC_NMI }, Vector { _handler: WIFI_PWR }, Vector { _handler: WIFI_BB }, Vector { _handler: BT_MAC }, Vector { _handler: BT_BB }, Vector { _handler: BT_BB_NMI }, Vector { _handler: RWBT }, // ...insert other vectors here ] }
Taking Peripherals needs to be atomic. Some boards do not support atomics, so the best way is to use software-defined critical sections.
The svd2rust documentation states that the take method used to get an instance of the device peripherals needs a critical-section implementation provided.
The take function looks something like this :
#![allow(unused)] fn main() { undone }
Abstraction aims
- Reduce the amount of unsafe blocks. Limit them to be as close to the registers as much as possible. Reduce them in as much as you can
- Abstract the true nature of the registers : Read-only, Write-only, Modify capabilities
- Hide the register structures such that NOT Any piece of code anywhere in your program could access the hardware through these register structures
- Ensure Volatile reads and writes.
- Handle concurrency gracefully using critical sections
- take by singletons
- repr peripheral with register-block - Name each regsiter
- register is a cell with volatile capabilities
- Reading requires a Read-proxy that can only access readable register sections
- You can access a bit OR bits OR enumerated value
- bit and Bits can be read or written using masks that have been enumerated.
- For unsafe arts, you can read or write to register sections with non-enumerated masks or bits. BUT they must be of the required bit-width.
- The Write method takes in closures and returns a writer proxy. This enables chaining of writes in one command. (kinda like the builder pattern)
- The write method can write bit, bit and enumerated value.
- modify method performs a single read-modify-write operation that involves one read (LDR) to the register using a read proxy, modifying the value and then a single write (STR) of the modified value to the register using a write proxy.
- The reset_function...
- resets the register under question
- returns the reset value for you to inspect if you need to
Generally, as will be seen going forward, PAC code takes the following form:
[Peripheral Handle].[Peripheral Register Name].[Operation]
PACs provide type-safe access to peripheral registers through API that allows manipulation of individual bits.
Enumerated values
If your SVD uses the
In the context of SVD2Rust, the
To determine if your SVD file utilizes the
Here's a simplified example of what such a section might look like in an SVD file:
<registers>
<register>
<name>CTRL</name>
<fields>
<field>
<name>MODE</name>
<description>Operating mode</description>
<bitRange>0-1</bitRange>
<enumeratedValues>
<enumeratedValue>
<name>MODE1</name>
<description>Mode 1</description>
<value>0b00</value>
</enumeratedValue>
<enumeratedValue>
<name>MODE2</name>
<description>Mode 2</description>
<value>0b01</value>
</enumeratedValue>
<!-- More enumerated values here -->
</enumeratedValues>
</field>
<!-- More fields here -->
</fields>
</register>
<!-- More registers here -->
</registers>
In this example, the
The PAC library produced might contain code that looks like this :
#![allow(unused)] fn main() { // Generated by svd2rust // Module for peripherals pub mod peripherals { // Register block for peripheral pub mod ctrl { // Register for the peripheral pub struct RegisterBlock { // Control register pub ctrl: RW<u32>, } // Register traits pub mod ctrl { // Read-write register pub struct RW<u32>; } impl RegisterBlock { // Method to create new instance pub fn new() -> RegisterBlock { RegisterBlock { ctrl: RW::<u32>::new(0x4000_0000), } } } // Field enums pub mod ctrl { // Enum for field MODE pub enum MODE { MODE1 = 0b00, MODE2 = 0b01, // More variants for other enumerated values } } } } }
MODE is an enum generated for the MODE field within the ctrl register. The variants of this enum (MODE1, MODE2, etc.) correspond to the enumerated values defined in the SVD file.
In your driver code, you might use the enums like so ....
// Import the generated code use peripherals::ctrl::{MODE, RegisterBlock}; fn main() { // Create a new instance of the register block let mut regs = RegisterBlock::new(); // Set the MODE field to MODE2 regs.ctrl.modify(|_, w| w.mode().variant(MODE::MODE2)); // Read the MODE field let mode = regs.ctrl.read().mode().variant(); // Match on the mode to perform actions based on its value match mode { MODE::MODE1 => println!("MODE1 selected"), MODE::MODE2 => println!("MODE2 selected"), _ => println!("Unknown mode"), } }
Interrupts
In SVD (System View Description) files, device interrupts are typically described within the
Here's a simplified example of how interrupts might be described in an SVD file:
<device>
<!-- Other device information -->
<!-- Interrupts section -->
<interrupts>
<interrupt>
<name>IRQ0</name>
<description>Interrupt 0</description>
<value>0</value>
</interrupt>
<interrupt>
<name>IRQ1</name>
<description>Interrupt 1</description>
<value>1</value>
</interrupt>
<!-- More interrupts here -->
</interrupts>
<!-- Other device information -->
</device>
And from the above svd, the svd2rust program might generate a PAC module that looks something like this :
#![allow(unused)] fn main() { // Generated by svd2rust // Module for interrupts pub mod interrupts { // Enum for device interrupts pub enum Interrupt { IRQ0, IRQ1, // More interrupts here } } }
You can then use this enum in your Rust code to handle interrupts in a type-safe manner. For example:
// Import the generated code use interrupts::Interrupt; fn main() { // Handle an interrupt let interrupt = Interrupt::IRQ0; match interrupt { Interrupt::IRQ0 => println!("Handling IRQ0"), Interrupt::IRQ1 => println!("Handling IRQ1"), _ => println!("Unknown interrupt"), } }
This interupt enums can be used with the microcontroller crates to enable/disable interrupts. For example,
#![allow(unused)] fn main() { use cortex_m::peripheral::Peripherals; use stm32f30x::Interrupt; let p = Peripherals::take().unwrap(); let mut nvic = p.NVIC; nvic.enable(Interrupt::TIM2); nvic.enable(Interrupt::TIM3); }
The RT feature
The RT feature enables the inclusion of the runtime-dependency during compilations. The runtime dependencie may be crates like cortex-m, riscv-rt.
The svd files contain additional info on interrupts that the board supports. So the svd2rust generates PAC code that adds this extra info onto the default vector-table that the rt-crate produced. It also provides a macro and an attribute to help you mark new interrupt handlers
Why does the PAC crate depend on a runtime crate?
If the rt Cargo feature of the svd2rust generated crate is enabled, the crate will populate the part of the vector table that contains the interrupt vectors and provide an interrupt! macro (non Cortex-M/MSP430 targets) or interrupt attribute (Cortex-M or MSP430) that can be used to register interrupt handlers.
Bench_marking
- benchmarking profile
- benchmarking commands
- file layout of bences
Closely related to benchmarking in Rust is the rust-testing harness :
A testing harness is a framework or set of tools used to automate the process of running tests on software code.
In the context of Rust, the testing harness refers to the infrastructure provided by the libtest library, which is included automatically when compiling tests using cargo test or rustc --test.
The rust testing harness does the following :
- Collects and compiles all the objects/functions marked with the
#[test]attribute. - Executes the chosen test functions
- It provides utilities/libraries/frameworks for writing tests. For example, when you are in a no-std environment, you may need a special testing harness to suit that environment
- At the moment, the default rust testing harness can also handle bench-mark functions. ie : (provide bench-framework*, compile
#[bench]functions, selectively execute#[bench]functions)
The harness field in cargo.toml manifest file
The harness field gets defined under both [[test]] and [[bench]] tables.
If the harness field is set to true, then the compiler will automatically include the test-harness as part of the compilation process and it will also include a main() function whose body executes the chosen benches and tests.
f the harness field is set to false, then Cargo will not include the default Rust test harness automatically. However, you are not required to provide your own harness and main file. Instead, you can write your own main() function to handle the execution of tests or benchmarks as you see fit. If you choose to provide your own harness, you can do so, but it's not mandatory.
Unanswered questions
- what is the default rust test harness? What can it do? What can it not do that is found in other established harnesses?
- Are there other established 3rd party std and no-std test and bench-mark harnesses.
- Is there a standrd test/bench-mark harness out there? possibly from the C/C++ world?
More on No-std.
I would like to write code that has very few dependencies.
The std-library is a dependency on its own. So I will avoid it whenever possible.
The core-library, alloc and test crates are dependency free.
This chapter just touches touches on these dependency-free library.
These are short-notes, you are better off reading the complete & official docs.
Core::mem
Just go read the docs to get the full picture.
Two ways to use this crate.
- To perform little tricks that can be done even without this crate. (discussed below under "Tricks").
- To perform analysis and manipulation of how data-types are laid out in memory. (discussed below under "memory_view")
Tricks
You can :
replacea value : Moves src into the referenced dest, returning the previous dest value.swaptwo values in memory - swap two values in memory without without deinitializing either one.- replace a value with a
defaultvalue andtakethe old value
core::iter
Turn any data-structure into something that you can iterate through. ie access things is a sequential and unit-wise manner.
You can turn a collection into an iterable-object ie turn it into an iterator.
To turn a normal data-structure into an iterable data-structure, you have to implement the Iterator trait for that struct. ie implement the functions found under the Iterator trait... give it some extra super-powers.
The core of Iterator looks like this:
#![allow(unused)] fn main() { trait Iterator { type Item; // The unit data structure. This is the unit of division. One unit == one step in our iteration process fn next(&mut self) -> Option<Self::Item>; // this fetches the next unit of division } }
When you define the iterator trait, the IntoIterator gets defined automatically.
#![allow(unused)] fn main() { impl<I: Iterator> IntoIterator for I { type Item = I::Item; type IntoIter = I; #[inline] fn into_iter(self) -> I { self } } }
Pre-defined Collections implement both the Iterator and IntoIterator trait. They have additional functions that are not found in custom structs.
These extra functions are :
- iter() - creates an iterator that uses
&Tsof the collection as its Iterator units. - iter_mut() - creates an iterator that uses
&mut Tsof the collection as its iterator units. - into_iter() // this function can be found for all iterators, it is not specific to Collections. It consumes the caller by value. It is useful when chaining Iterator-operations.
The for loop and the match statement use the into_iter function by default. So they consume the Iterator or collections that get passed to them.
A token tree is different from an AST. We can have leaf-token-trees and non-leaf-token-trees.
Token tree generation happens before the AST generation happens. This is because the AST is constructed from the token tree.
Macro processing happens after the AST tree has already been generated. So macro invocation must follow a certain syntax
There are 4 syntax ways of invoking a macro:
# [$arg]# where$argis a token tree. eg#[test]#! [$arg]# where$argis a token tree. eg#![no_std]$name ! $arg# where$argis a non-leaf token tree. egprintln!("sdkfjskdf")$name ! $arg0 $arg1# where$argis a token tree. egmacro_rules! custom_name { // magic_lines_go_here }
Macros can be of differennt types. Here they are :
- Attribute macros
- Function-like macros
Attribute Macros
Attribute macros are used to either tag things OR to derive things.
The #[test] attribute macro is an example of an attribute used in tagging. It is used to tag/annotate that a certain function is a test. These tags are relevant to the compiler.
The #[derive(Degug)] attribute macro is an example of a macro used to derive things. It is used to automate the implementation of the Debug trait for any tagged object.
So if we decide to classify attribute macros based on fuctionality, we would have two classes :
- Attributes used for tagging purposes.
- Attributes used for automatic derivations.
Attribute macros can be declared and defined through a couple of ways.
- They can be hardcoded as part of the compiler code.
- They can be defined using proc_macro crate. This crate provides for you functions that can manipulate the AST of rust code. With this crate, you can create macros that manipulate the AST ie
procedural macros. - They can be defined using normal rust code that uses the
macro_rules!declaration syntax. This method allows you to define how yourcustom syntaxgets expanded. ie How a string of syntax gets translated into a token tree. This macro-declaration method is calledMacro-by-exampleorMacro-by-declaration. Weird names. I guess its because you explicitly declare how your syntax gets expanded.
From the above info, you are right to think that you can write your own derive attributes and tagging attributes.
So if we decide to classify attributes based on how they were created instead of their functionality, we would have 3 classes :
- Built-in attributes
- Proc-macro attributes
- Macro-rules attributes
To read more about attributes read the Attributes chapter from the Rust-reference book.
Function like macros
These are macros that have functions underneath them. For example println!, format!, assert!.
These macros can be defined just like the Attribute macros ie. You can either use the proc_macro crate or the macro_rules! declaration syntax.
What can be represented by a syntax extension (ie a macro)?
Macros are allowed to expand into the following :
- An item or items
- A statement or statements
- A type
- A pattern
- An expression
The macro expansion is not a textual expansion, It is an AST expansion. Expansions are treated as AST nodes.
Expansion happens in "passes"; as many as is needed to completely expand all invocations.
The compiler imposes an upper limit on the number of such recursive passes it is willing to run before giving up. This is known as the syntax extension recursion limit and defaults to 128.
This limit can be raised using the #![recursion_limit="…"] attribute.
Macro Hygiene.
We have seen that a macro gets expanded as an AST node.
A macro is said to be unhygienic if :
- It interacts with identifiers and paths that were not defined within the macro
- It exposes its local paths and identifiers to be accessible by code outside the macro
A macro is said to be hygienic if :
- It does not interact with Identifiers and Paths that were not defined within it
- It does not expose its identifiers and paths to be accessible by code outside the macro definition.
Debugging Macros
You can preview how your macros got expanded using rustc's -Zunpretty=expanded flag. This flag is curently available in rust-nightly only.
like so :
rustc +nigthly -Z unpretty=expanded hello.rs
Macro Rules
the rules of the macro follow this syntax :
#![allow(unused)] fn main() { (bunch of token-trees) => { expanded token-tree structure } }
You can use metavariables that have types attached. Read the "little book of macros" to understand this.
You can also supply tokens to the matcher like a regex expression or something.
Repetitions are shown using the syntax : $ ( ...token-trees that need to be repeated... ) sep rep where
untouched
- Embassy Framework
Codegen
Rust has a toolchain that can be tweaked. Most of the time you'll be tweaking the compiler itself.
Understanding the Codegen properties
HDLs
Levels
- Behavioural Langs(describe inputs, outputs and expected behaviour)
- RTL (Register transfer Language): describe hardware in terms of sequential and combinational circuits
- Gate-level languages: describe circuits in terms of interconnected individual gates
- Transistor-level langs: describe circuits in terms of interconnected transistors. (Gates ca be composed of transistors)
Interfaces
- CAN: Interface to CAN bus peripheral.
- Ethernet: Interface to Ethernet MAC and PHY peripheral.
- I2C: Multi-master Serial Single-Ended Bus interface driver.
- MCI: Memory Card Interface for SD/MMC memory.
- NAND: NAND Flash Memory interface driver.
- Flash: Flash Memory interface driver.
- SAI: Serial audio interface driver (I2s, PCM, AC'97, TDM, MSB/LSB Justified).
- SPI: Serial Peripheral Interface Bus driver.
- Storage: Storage device interface driver.
- USART: Universal Synchronous and Asynchronous Receiver/Transmitter interface driver.
- USB: Interface driver for USB Host and USB Device communication.
- VIO: API for virtual I/Os (VIO).
- WiFi: Interface driver for wireless communication.
community_links
- https://www.devicetree.org/
- openTitan
- Flattened Device Tree (FDT) form.
- Cheri